I thought I should put together some of the thoughts we’re having in the ArduPilot dev community regarding UAVCAN v1.0 versus the existing v0 protocol. I’m one of the people leading the effort for UAVCAN in ArduPilot, and so far I’m not convinced that embracing 1.0 is the right thing for us to do, as it would be highly disruptive just at a time when we are finally getting wider usage of UAVCAN.
The key pain points of the existing protocol from my point of view are:
- lack of message extension
- lack of dialect negotiation
I’ll give some examples of these pain points to illustrate.
Many of the issues with v0 uavcan can be illustrated by the gnss::Fix and Fix2 messages. The issues are:
- the switch from Fix to Fix2 was done to add RTK status bits (mode and sub-mode), plus changes to 32 bit float for velocity and changing covariance representation.
- we should have been able to extend Fix by adding the extra status bits without creating a whole new message. As uavcan didn’t support that, we ended up with both messages, and so GPS UAVCAN modules need to send both and flight controllers receive both, with no obvious path to ever get rid of the first message. That is not great.
- for mavlink2 I added in the concept of message extensions, allowing for additional fields to be added to messages without breaking existing recipients. If a sender doesn’t know the extra fields then the recipient sees a zero value in those fields (the semantics of zero values needs to be chosen carefully to cope with this)
- these message extensions have allowed us to evolve mavlink2 to add additional fields while maintaining compatibility. Just look for ‘extensions’ in the xml for examples.
- we also have a capabilities message, which allows a flight controller to announce what new elements of the protocol it supports. This allows a GCS to know if it should use a newer protocol element instead of an older one. That helps a lot.
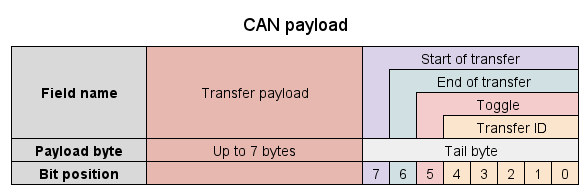
These concepts should be baked into uavcan. It is especially important for traditional 1MBit can as the bandwidth is often very constrained, especially given the huge encoding overheads (effectively under 0.5MBit). Wasting bandwidth by sending multiple almost identical messages is a very non-scalable way to handle communication on a limited bandwidth medium.
We’ve also found it painful to deal with the v0 messages due to the way they over complicate things. The Fix2 message with its numerous ways of representing the accuracies is a good example. Does anyone really want a 6x6 matrix? I know you can use the 6 element form, but it was really silly to go with such a general representation on a transport with such limited bandwidth when the real world use cases are just 3 numbers (horizontal accuracy, vertical accuracy and speed accuracy).
Similarly with RawAirData for airspeed. We only need 2 numbers, a pressure and a temperature. It has two pressures and four temperatures, plus a 16 element covariance matrix, none of which is clearly specified. It’s like a parody of a normal limited bandwidth comms protocol. What should have fitted into one CAN frame instead takes a pile of frames and leaves developers scratching their heads as to how to fill or interpret the fields.
I suspect the lack of message extensions is what led to the over specification of messages like this. The person who makes up the message needs to think of all possible corner cases because they know they will have no sensible opportunity to fix it without having to create AirData2, AirData3 etc. If we had extensions then we could have started with the very simple message, and if their really was a need for the extension once the message is in use then add it without breaking the existing usage.
I know this is complicated by the seeding of the crc with the message structure signature. Mavlink has that as well, and I got around that by limiting the crc seeding to be based on the part of the message structure that is in the ‘core’ message (ie. with no extensions). That leaves the extension vulnerable to two devs adding different extensions, but it is a practical method that covers most of the things we care about while still giving us the ability to add extensions.
I’m the first to admit that the mavlink2 extension system was not ideal. It was designed to fit within the constraints created from the history of the mavlink 0.9 and 1.0 protocols, while maintaining API compatibility as closely as possible and allowing for mavlink2 and mavlink1 to co-exist on the same transport. For end users it was a huge win, as it “just works”, and now they find that extra info turns up on their GCS displays that wasn’t available before.
At a lower level we may have been better off using something like DER encoding with ASN.1 structure. While lots of people dislike ASN.1, it does have really nice mechanism for extensions while also being able to create reasonably efficiently packed messages.
Anyway, now that I’ve explained the pain points with v0 I’ll give my perspective on v1. I have yet to see anything that suggests that v1 actually addresses the above pain points. I also don’t yet see how we are going to give a smooth migration path for our existing users onto v1, especially if they have UAVCAN devices with low amounts of flash. Our uavcan bootloader is currently around 18k (including DNA etc), and is based around libcanard. The available flash space for bootloader on existing devices is 23k. So we have 5k to add support for dual-stack with v1. Is that possible? If it isn’t then moving to v1 is a non-starter as we can’t get users to setup debuggers to change bootloader, and we need dual stack anyway so they have a smooth path to try a new v1 capable firmware but can move the device back to the old firmware if things don’t go as planned.
Doing dual stack in the flight controller will be possible for the boards that have 2M of flash. For boards with 1M of flash it will be tight, but may be possible (the old Pixhawk1 with the 1M flash bug does still matter for us as a use case). Dual stack in a stm32f103 can node is a much harder proposition, as we have only a few k of spare flash, and very little free ram. We really don’t want to force hardware change on our users yet again.
For those who haven’t seen it, this is one of the key pieces of our UAVCAN ecosystem push for ArduPilot:
It is basically ArduPilot running on CAN nodes, using all the standard ArduPilot sensor libraries, but on small footprint MCUs like F1 and F3. The aim is to make it really easy for vendors to create new UAVCAN peripherals. They just need a hwdef.dat to give the pinout, and they need ArduPilot to support the sensor they want on UAVCAN. Then creating the firmware is trivial.
We’re making a big push at the moment to get lots of vendors to make peripherals based on this and we’re just starting to get momentum. A shift to v1 would likely stall the progress we’re making, which could kill off UAVCAN as a viable system for wider adoption for a long time. That isn’t attractive.
Anyone, that’s probably enough for now. I hope it was helpful in showing our perspective.
One final note, I am hugely grateful for the effort you and others have put into UAVCAN, and I realise my contributions have been trivial by comparison. None of the above criticism of v0 and v1 should reduce the fact that your efforts over many years have made what we’re doing now possible. We just need to make engineering decisions based on what we see as being the key factors for us now.
Cheers, Tridge