No, frames per second. A message can be split over multiple frames.
There will be different communication protocols so it shouldn’t be dependent on CAN 2.0. In the old GUI tool, the graph rescales itself automatically, it’s probably best to keep this behavior unchanged.
Do you want to keep the data hex and data ascii ? (I guess so).
The last remaining things to chat about design and ux considerations would be the dynamic node allocation widget, message logging and subscribing widget.
I guess it makes sense to just keep a dictionary of node ids <=> uids. Do you want to support reassigning uids as well? (Is that even supported?).
The message logging part could be part of the can bus monitor, by just applying filters like the designed ones on the plotter. I’m not sure if you prefer this to be a different component.
One extra idea would be a message ‘emitter/debugger’ to post messages (periodic, from csv or whatever), after evaluating some javascript. We can have some defaults and also support vendors too. For example, a sawtooth wave curve to test motors or…
Sure. Keep in mind that if we decided to support Ethernet (I’m pretty sure we’re heading this way), the maximum frame size may be up to 9000 bytes.
The allocation table could be just a plain array of UIDs, where the index matches the node ID. Relevant specs:
Reassignment of UID is not formally defined, so it’s safe to leave it out. The user must be able to wipe the allocation table though if needed. Ideally it should be possible to store the allocation table in a file (persistent) or in memory (forgotten after a restart).
I understand that by message logging you mean the subscription tool (rather than frame logging). I think it should be a different component because we can’t know the ratio between the desired message rate and the total frame rate on the bus. If it’s small, the tool will have to sift through copious amounts of data on the bus in real time just to cherry pick the few messages the user cares about. It won’t scale well. Instead, I suggest to implement it based on regular subscription logic, allowing PyUAVCAN to deal with the real-time filtering part (it has access to the interface configuration, so it can employ hardware acceptance filters as necessary).
As in the case of frame logging, we shouldn’t stream anything in real time:
That’s only for display purposes? Are we going to add an action endpoint to upload pre-existing allocation table?
Displayed values should be truncated? (hover over to preview full hex and ascii representation is possible, but a bit unnecessary in my opinion since you have the click-to-view-data-tree feature)
Ok. What query parameters are going to be used? Pagination, time constraints, … ?
Can pyuavcan dynamically reconfigure it’s id on runtime? I’m asking because I’m considering to add a /restart and /reconfigure endpoint for the backend, in order to change params like log directory location, bus id, log rotation times, whatever comes up.
I think it’s best to postpone that until much later. Not sure if it’s that useful.
You can’t apply a data tree view to a single frame, because a frame is not guaranteed to contain an entire serialized object. The purpose of the bus monitor is to provide a very, very low-level view of the data, like a hex editor.
The message view that appears in the bottom-left corner of the old gooey tool does not necessarily apply to the currently selected frame only. The old tool detects which frame is selected, then walks up and down the list of frames to reassemble the transfer that the selected frame belongs to, then deserializes it and displays the result. So it is important to keep in mind that the bottom-left view is more complex than just a decoded single-frame payload.
I think the most common use case would be where the request is constrained by a time boundary (either upper or lower) and the maximum number of items to return. Like select * from rows where timestamp >= x order by timestamp limit 1000.
If the user is scrolling the view towards the bottom and reaches the end of the locally available data, the frontend would look at the last loaded entry, pick its timestamp (let it be X), and request the next chunk where timestamp >= X and the max number of returned elements is 1000 (surely any decent computer can chew 1000 items at a time?). The frontend should also drop some frames from the opposite end of the view if it exceeds some sensible threshold (say, ~5k? assuming 9000 bytes per frame in the worst case, that would be 43 MB of locally stored data).
If the user is scrolling the view in the opposite direction, the logic would be pretty much the same except that we’ll be looking at the top entry’s timestamp instead of the bottom one and the boundary will be specified as (timestamp <= X).
If the user desires the view to auto-scroll in (quasi) real time, the frontend would just poll the backend every second or so, simply requesting the latest available entries.
We will need to define a simple and extensible log dump format. It probably makes sense to use log files in that format as the underlying storage for the bus monitor & frame logger as well, so that the backend would store received frames in a rotating collection of files in that format (say, we could keep only the last few files, a couple of gibibytes each, removing the oldest ones automatically unless configured otherwise); when the front-end requests a particular slice, the backend would just open the matching file and return the matching frames from there. If the frames are ordered by timestamp (there is no reason for them not to be, although the backend should be prepared to properly handle short-term out-of-order frames received from the underlying driver, this is easy to do by keeping a short (say, 1k frames) buffer in memory before committing it into the file), the backend can navigate around the file in O(log n) using simple binary search. If the user desires to store a dump locally for a later study, it would just pick the boundary (say, timestamp between X and Y, but no more than Z frames; or just N last frames) and the backend would return the matching slice.
I particularly like the idea of defining a very minimalistic headerless file format which simply contains a sequence of frames, each with its own dedicated header and CRC. This would allow the user to easily manipulate log files by truncating or concatenating them naively, no special tools needed.
That said, I don’t have any particularly strong feelings about this approach. If you prefer having a proper database for temporary log storage, go for it. In this case we could still generate a log file in our to-be-defined minimalistic format upon request, dynamically.
I should sit down someday soon and seriously think about that format.
That would require us to instantiate a new node (destroying the old one), otherwise yes. UAVCAN is a very static thing (because it is designed for robust embedded systems), it does not define dynamic reconfigurations.
Does being able to POST new configuration and restart yukon backend sound like a new idea?
I’d much prefer to have some database of a kind and add the ability to export data as log files or over json on demand, but let’s postpone that part till the other parts are in a more complete state.
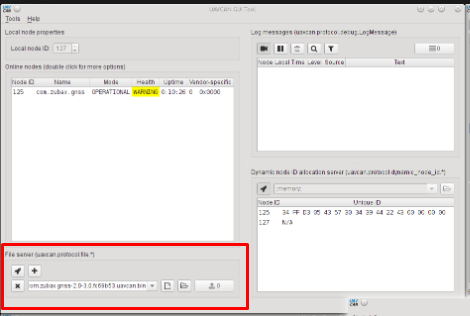
What’s the purpose of the file server on the old gui_tool?
I think the rest api interface is close to it’s final state: swagger link
Sure, but we don’t need to restart the whole backend. We just need to instantiate a new pyuavcan.Node and destroy the old one. We may even keep the interfaces running, but I am not sure (I’m yet to get to that part).
We need the file server for firmware updates:
Which reminds me that if the server is running on a different machine, the user should be able to somehow upload the file to the server via the GUI.
The file server may be useful by itself irrespective of the firmware update feature.
Another question: Type info caching during development of new types. If someone is going to use Yukon while developing new uavcan types at the same time, caching should be done on the browser’s cache that can be easily cleaned-on-refresh (example, on chrome: ctrl+shift+r / hard reload)?
Instead, we can always schedule type updates in the background, using types that exist in the cache and re-pulling everything from the server. That sounds like a bad idea and does not add much to the UX. Perhaps we can add some Cache-Control headers on the server-side with a variable ttl for each type: Practically infinite for UAVCAN public regulated ones, no caching for ones that are under some special dev folder (or if the folder contains a .nocache file?), a month or a day for other private unregulated ones.
Both parts of Yukon are probably going to run in the same machine while doing development, it should be pretty easy to just directory junction the paths that the backend is going to look at for the type info.
I don’t know what would be the best strategy. I think we can safely rely on the browser’s cache as you described in the beginning of your post, it seems sensible.
I don’t think it’s a sensible idea to require specific directory names or files, because due to the nature of DSDL it is expected that stable types will be sharing directories with unstable ones. You can always determine whether a data type is stable (i.e., safe to cache) by looking at its major version number: zero means unstable (don’t cache or use a low expiration timeout), anything >0 means stable (safe to cache forever or (better) until restart).
@Zarkopafilis I couldn’t run the changes from your pull request locally because the module @/Router is missing:
ERROR Failed to compile with 2 errors
This dependency was not found:
* @/Router in ./src/main.js, ./node_modules/babel-loader/lib!./node_modules/vue-loader/lib/selector.js?type=script&index=0!./src/App.vue
To install it, you can run: npm install --save @/Router
^C
✘-INT ~/uavcan/Yukon/frontend [:4d5c7aa|✚ 2]
21:54 $ npm install --save @/Router
npm ERR! code ENOLOCAL
npm ERR! Could not install from "@/Router" as it does not contain a package.json file.
This thread is not the right place for this post, but I couldn’t comment on the pull request because GitHub is malfunctioning (it’s weird, I click the “Comment” button and my text just disappears, come on Microsoft!).
@pavel.kirienko The idea for the streaming approach is as follows:
Now that vuex is inside the project, we have enabled a state management system that is accessible from outside of the component hierarchy scope, for all of the app’s lifetime. This enables us to initiate a websocket connection on the background, which update’s the state, with that being decoupled from each component.
This kind of websocket connectivity should be fire-and-forget on the backend side.
For example, on the homescreen part, when the app is firstly loaded, each component does a get request in order to load information about the server, the pnp table and the node list.
Using websockets, these can then be updated on the background even when the user is on a different tab. Support for each and every component is not required. For example, we can only implement this functionality for stuff like the node list and the plug and play.
I’m investigating possible architectures and writing tests.
On the python side of parts, you just add connections on to a set and then, on each event, you broadcast updates to each and every connection.
On the js side of parts, you just use an EventSource
I currently have experience with React Native, React, Redux, and Sagas. I see that you decided to use Vue and Vuex. I can invest some time learning about Vue in order to help out.
I’m curious to know if you considered using GraphQL instead of REST for the API?
Hello. It’s very nice to see new people coming abroad. We evaluated React for the project and ended up using vue over it, due to licensing and slightly better developer experience.
Personally I have evaluated GraphQL as a solution for the project. The problems it’s designed to solve are:
Consuming data from multiple sources
Avoid the need of reconstructing (mapping) objects in the frontend
… through an extra layer of abstraction.
Any webapp of medium size is going to have some kind of relation projected over REST endpoints. That aside, you can tell by just looking specific components that ql is not going to provide significant advantage (look at the Global Register View for example – the mappings and computed properties are huge).
Same thing with the “simpler” components: The 4 ones that make up the homescreen, for example. Yes we could debate over doing 1 call over 4 ones (1 for each sub-component). The 2 ones are really a couple of bytes and merging the other 2 would not make such difference. It would also make it a bit harder to separate concerns between components, require the logic of “splitting” the response inside the vuex/actions in order to update the correct module’s state parts.
I’m still open to using it if you find a proper use case: But for now, I see no valid one.
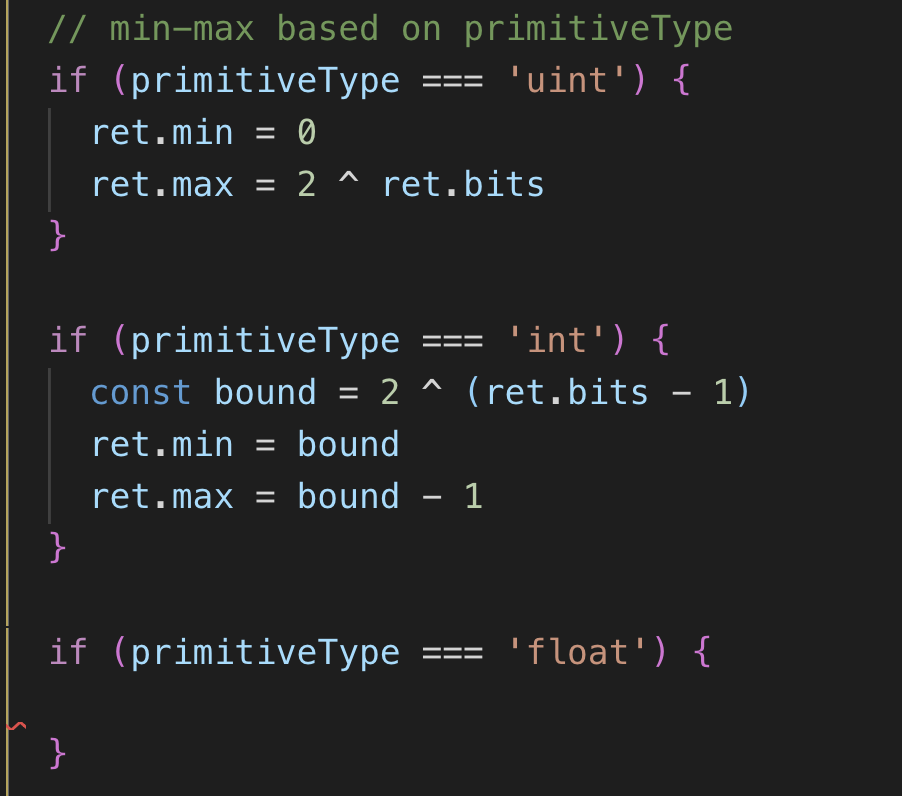
I unsure of what float format you are using. Do you have some spec or a formula that I can swiftly calculate min and max number for floats? (JS has only got a ‘number’ data type, per IEEE 754.
You seem to be missing a minus-one in the uint case. The upper boundary (assuming that it is inclusive) should be 2 ^ ret.bits - 1. In the int case, the lower boundary should be negated.
For floats we use three formats defined in IEEE 754: binary16, binary32, and binary64. Their maximum values are defined as follows:
where frac constructs a rational number for exact computation; if you don’t require exactness, feel free to omit it.
The minimum values can be found by negating the maximums.
I am wondering though, would it not be easier to just obtain type information from PyDSDL instead of computing everything in JS? Just asking.
It’s just for computing some min/max stuff for form generation/input validation. We can swap it out if it turns to be a problem.
GRV is progressing fast, I guess I am adding a hover-over to view full tree of each register.
Does a click-register-truncated-value-to-add-to-workset ux sound good?