The Yukon project is currently suffering from a lack of well-defined long-term vision which complicates planning and management. In order to address this, we just convened with @TSC21, @arrowcircle, and @ivodre, and drafted out the following plan for the immediate future:
Nuno will document the activities outlined in the active Statement of Work that he has agreed to with Amazon on GitHub to ensure that they are visible to the other team members.
Oleg and Nuno will be collaborating on the above activities as they see optimal. In particular, Oleg will focus on rectifying the shortcomings of the existing CI/CD infrastructure. I have requested Scott to grant us more autonomy on tool selection.
Ivo will familiarize himself with the context, read the existing relevant discussions on this forum, skim through the UAVCAN specification, and decide whether he wants to commit to this. If yes, he will join the project in the form of a project manager or a product owner, defining the abstract project documentation and deriving low-level requirements such as storyboards, etc, as well as performing other related tasks appropriate for a PM/PO.
Here is the list of the reading materials for Ivo:
Nuno is also going to share some materials related to SCRUM separately.
The group will reconvene on Monday, 17:00 EEST / 16:00 CEST at https://whereby.com/Zubax. Somebody will post the notes from the call here.
One thing we should discuss at the next call is whether it is possible to aim for a minimal practical demo to be presented at the upcoming PX4 Developer Summit.
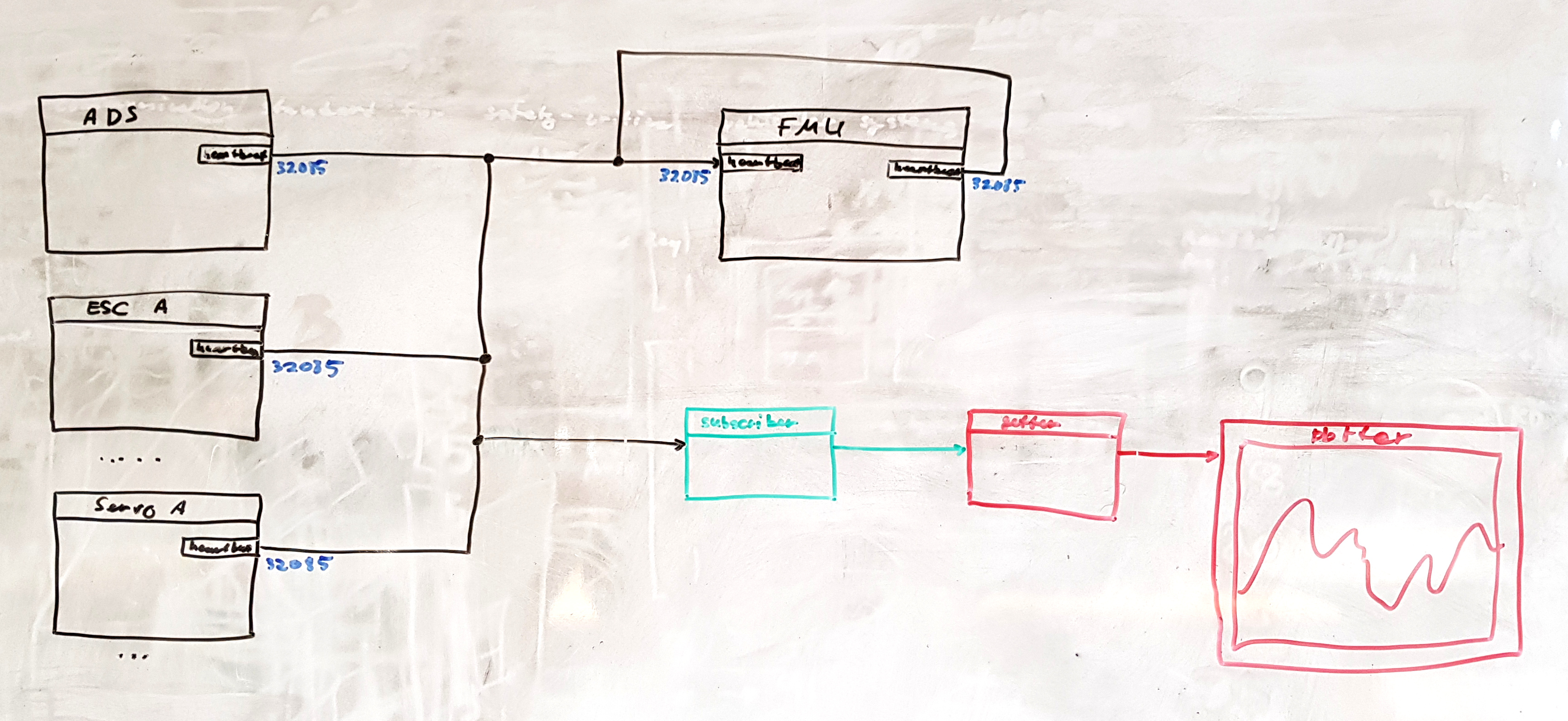
@arrowcircle says that the number of project management boards on GitHub should be reduced. He also says that we need to define concrete requirements for the demo canvas mock-up starting with the exact list of nodes; we agreed to model a trivial tailsitter containing the following nodes:
one FMU
four ESC
two servos
one airspeed sensor
The exact subjects and services are TBD.
@arrowcircle should look at the ROS Computational Graph documentation to better understand the concept of real-time distributed pub-sub:
It is hard to organize our activities because we still don’t know what the specific objectives are. @ivodre is going to help us here. He is willing to invest up to 15 hrs/week (best case) into this project but the duration of this commitment is unknown. We are unable to determine what is the required minimum level of involvement from his side as a product owner so we are a little in the blind but hopefully things will clear up in the near future. Ivo will be asking questions via Slack until he has a clear picture of what we are trying to do, I will make sure to accommodate. While @tsc21 & @arrowcircle are working on the demo, @ivodre will be learning the background and then working on formulating the plan & requirements.
Regarding the PX4 summit: @tsc21 is hesitant to commit to anything citing conflicting personal arrangements so at the moment we are going to avoid stating anything related to Yukon but will keep our options open; hopefully the organizers will be flexible enough to admit late replanning.
As discussed, Ivo is expecting to get sufficiently involved by the end of the current sprint, which means around early July. Meanwhile he is observing the ongoing work.
OIeg is going to submit pull requests fixing the CI/CD issues as already mentioned here earlier. He is supposed to have full access to Buildkite now.
The next call is tentatively planned to Friday 17:00 UTC, pending confirmation from @arrowcircle.
We have a new record – approx. 2h on the call. There should be an emoji of a unicorn puking rainbow.
Tomorrow morning @tsc21 will be working hard on defining the low-level requirements for the current sprint. We may or may not have another call to discuss that afterward.
Here is the image of the drawing I made on the (not so) white board:
The local data manipulation entities – namely, the subscriber, the getter, and the plotter – are outside of the scope of the current sprint but the design shall allow their introduction later.
Today’s dev call recap (only the parts related to Yukon).
Nuno has prepared the tasklist for us; it is published in The Second Sprint Thread. Thanks, Nuno. The task list seems uncontroversial excepting two things:
On the canvas, left-side node connectors should be inputs (subscriptions, service server requests, service client responses), and right-side connectors should be outputs (publications, service server responses, service client requests).
Oleg points out that the tasklist lacks detail and rigor.
For the next days, Nuno will be focusing on the backend while Oleg will finish the CI/CD infrastructure setup (having extended the tasklist with relevant entries beforehand because we need to be aware of who is working on what exactly). We have a go-ahead from Scott to move forward independently without requiring explicit approvals for every change as long as we take care not to compromise the security of the auto-release pipeline accidentally.
Oleg points out again that the frontend is encumbered with unnecessary dependencies many of which have gone obsolete but we will not be addressing this right now yet.
We might set up another coordination call depending on how things go. We will need Ivo to join as well because we don’t want him to fall out of the loop.
Ok, I am moving two questions from it’s original google docs to the forum (posting also the replies given as comments so far so far):
Question 1:
What is the reason for the KPI discussion? Why do we care about CPU usage if we are on a computer (which I assume has plenty of computational resources)?
Is it maybe related to this forum post: While we’re listing deficiencies: one problem with the old design is that the UI often becomes unresponsive when attached to a very busy system. Remember that some views will be dealing with things that can number in the many hundreds of thousands and that can change at very high frequencies. Because of this, it’s essential to avoid creating performance bottlenecks across the REST interface. The UI must deal with paged views into large datasets and the python server must provide ways of coalescing high-frequency events before updating the state of the UI.
Pavel: Correct, no other reasons
Ivo:
Can I understand a simple KPI example (using your language) like this: KPI threshold: 1 gazillion messages/second. KPI: currently we are processing X gazillion messages/seconds. KPI test: is our system working well as long as KPI<KPI threshold?
I guess the follow up question is what Nuno talked about in one of the past calls: what should the KPIs be?
Anonymous:
Ivo, the KPI’s discussion isn’t finished yet and I have not retrieved enough information to understand what KPI’s to use.
Nuno:
The KPI’s are not used to measure the protocol performance. They are used for example to measure what can be the influence of the current Yukon implementation on the measuring tools that will be available in the application. This is a way of understanding how much of the observer effect will we have to take into account, and if it’s reasonable or not. If it’s not, the stack (backend and frontend) might have to be optimised or certain parts changed.
I have some unclarity regarding the mock session description and simulation (Issues #49, 50)
Issue #49: why do we need a data format for simulations? Can’t we just log what is happening on the bus and write code to build display the content of the canvas based on that? And if we do that, what is the difference between this new description we create and a log of the data on the bus?
One answer I can imagine is that for the KPI tests we want more data flow than what happens usually on the bus, so we need to make artificial nodes.
Another one I can imagine is that that’s harder to do than mocking it up or that we don’t even have a way to log everything that happens on a bus, because we would need one node that subscribes to every subject and receives a copy of every request/response of service calls.
Third reason: we want to be able to simulate behaviors without any hardware.
Are these the main reasons? Are there more reasons?
What does the simulation (#50) actually do?
i.e. what does it mean “to consume the mock-session-description data to drive a simulated bus on top of PyUAVCAN.”
Pavel:
I think we haven’t yet explored this question in detail so there is much open to interpretation/discussion. I will pick this up on GitHub issues.
Create an example test that loads the system description, defined on the chosen format, on the backend. This test should be run manually. Addition to CI is an extra;
What kind of tests are you talking about?
Nuno: A python script that loads a system description in the backend and a Python test framework, we can evaluate the KPIs
I decided to publish a list of what I would like to discuss in the call tomorrow. If you have the rights, feel free to edit/add other things (otherwise maybe post it in the replies and I edit this post)
Questions
Understand the discussion about session description and simulation
Besides the questions mentioned already, I am not sure if I understand the meaning of simulation in this context. In my understanding Simulation means you have a certain amount of prediction involved (be it climate models or a flight simulator). As far as I understand what we call simulations here is a sort of “replay” of something that is happening or happened on the bus (or am I missing something?).
Understand if I need to understand KPI stuff now? If yes make sure to understand it.
Create an example test that loads the system description, defined on the chosen format, on the backend. This test should be run manually. Addition to CI is an extra;
Q: What kind of tests are you talking about? A: A python script that loads a system description in the backend and a Python test framework, we can evaluate the KPIs
Secondary questions in google docs
DevOps questions remaining after readings proposed by Nuno
Required depth of understanding
discuss about timing and priorities
Logging:
after reading #74
should logging be only possible in pyuavcan or also in embedded version of uavcan?
if only in pyuavcan, can we plug a computer running pyuavcan onto the bus and log stuff going on there? How would that work?
Vision of usage of Yukon. User stories.
Admin
Crosscheck that nothing is missing/extend github issues based on new task list for sprint 2
When is next sprint going to start. plan back from then.
How should we go regarding the next steps? I suggest I focus on better understanding the usecases of Yukon during this week, and then start thinking about how to achieve them next week. Does hat make sense?