Hi Pavel, I’m interested in helping with PyUAVCAN. I tried looking for a dev branch on PyUAVCAN’s GitHub repo but couldn’t find one. Could you point me to where this new version is being developed?
I’m not sure if it would be better. I’ve been trying to think about some possible benefits of using graphql, like for example using nunavut to generate the schema (types, queries and mutations) automatically from the dsdl. However, I’ve just started learning more about the uavcan spec, so I haven’t really thought about all the possible limitations/implications.
You are right, since we would need to declare all fields in the query this could be impractical for the GRV. However, queries could be automatically generated. I will think more about this to see if it is feasible.
Yes, it would be impractical to update the vuex store from the graphql results. In the case of using graphql it would be easier to use a client like apollo instead of vuex.
Ok, I will think more about those features and will reach out.
Ok, will do!
Totally possible.
That would do for now. I was thinking that we could maybe check for the first non-file request UAVCAN message with source ID equal to the one of the node that was previously updating, in order to determine online status.
That would then require to export every existing thing again for Yukon usage. Exporting into JS- friendly format would not make much sense too, you’d still have to parse that in order to generate forms. I know graph ql supports ‘recursive’ calls in some sense but I would not rely on it or give away flexibility. There is also much hidden complexity with the version types and other stuff which we have discussed already in this forum post.
Vue supports recursive components and computed properties, so this is no problem. I encourage you to look into TypeInput and TypeEditForm to get some insight
That would introduce the same complexity that graphql would, without giving back much advantages. Vuex is also tightly integrated with vue.
That’s also needed, but I was asking for the more simple format, of copying a TypeValue. For now, the server returned type is copied to clipboard along with the _type_, it could be handy to maybe export it in yaml or csv, or something else, idk, everything is possible.
I took a look into the spreadsheet you posted, it looks OK. It seems like that on the gui_tool, only CAN frames are shown, I am thinking of a design that could show all the frame types, without that being visually noisy. Do you have any recommendations for that?
Just finished implementing Server Sent Events Foundation. Turned out pretty clean.
The devlopment is currently happening in my fork: https://github.com/pavel-kirienko/pyuavcan/tree/uavcan-v1.0. Seeing as you are interested, I should move it into the UAVCAN org. I am going to open tickets for coordination afterwards.
Online nodes can be detected by listening for uavcan.node.Heartbeat – every UAVCAN node is required to publish this message at least once per second. When the uptime value reported by this message leaps backward, we know that the node has restarted. This, however, is unlikely to help with the software update tracking since a node does not necessarily have to restart to apply the updates.
You seem to be talking about a different feature. The format I described is supposed to store raw data frames without any higher-level data whatsoever. This is what I am suggesting for use for data log storage. If it ended up being accepted, we will need to eventually teach Yukon how to open such data logs and extract application-level information out of them. For now this is not yet critical.
I do. Suppose there are the following columns in the log:
- monotonic timestamp
- UTC or local timestamp (see below)
- transport frame header
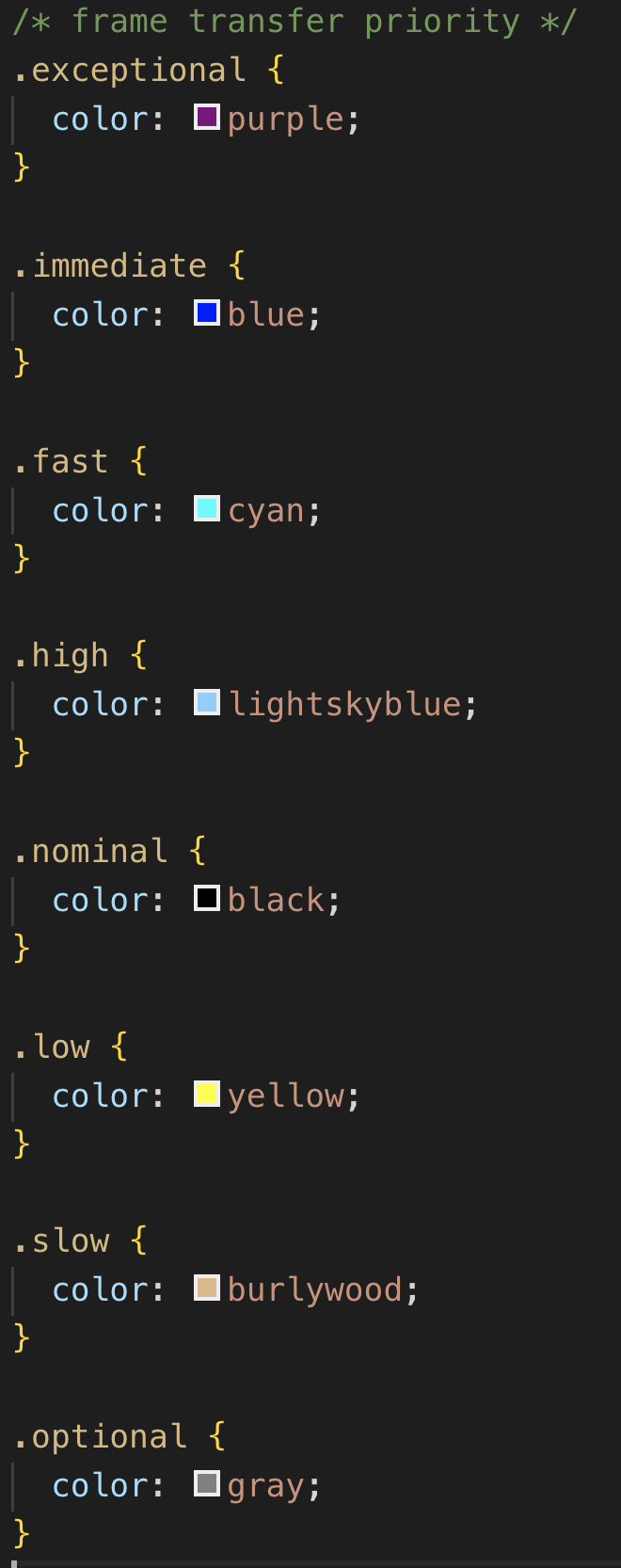
- priority level name per the spec (exceptional, immediate, fast, high, nominal, low, slow, optional)
- route specifier:
- source node ID
- destination node ID (empty for broadcast)
- data specifier:
- if message: subject ID
- if service call: service ID and request/response selector
- data type name and version (the mapping from subject/service ID is to be defined by the user or auto-deduced by parsing the logs)
- transfer ID
- data in hex
- data in ASCII
If you are curious where did “route specifier” and “data specifier” come from, read this: Alternative transport protocols, there is a diagram.
Obviously, UAVCAN may share the same medium/transport with other protocols, so it is expected that for some frames we will not be able to determine “route specifier” and “data specifier” because they have nothing to do with UAVCAN, so the respective columns will be left unpopulated.
Now, the column “transport frame header” is supposed to contain the low-level transport frame information in the raw form, completely unprocessed. Hence, its contents will be dependent on the kind of the transport protocol in use. Per the table I linked from my previous post, the values would be at least the following:
- For CAN bus:
- CAN ID
- flags: extended or base frame, RTR frame, error frame, CAN FD frame
- For UDP/IP (lots of data here):
- source endpoint (IPv6/v4 address, MAC address, port)
- destination endpoint
- For IEEE 802.15.4:
- source MAC address (64 bit)
- destination MAC address
- source short address (16 bit)
- destination short address
- RSSI indicator
For consistency, I suppose all that data should be squeezed into one column.
UTC/local timestamps are tricky. If you look closely at my proposed data log format, you will see that it only mentions a “monotonic timestamp”, which has no well-defined starting point and its only purpose is measuring time intervals between messages belonging to the same recording session (where recording sessions are separated with special records where the transport ID is zero). It is important to stick to monotonic because globally managed time such as UTC or GPS is not always available, yet we don’t want to pause logging if the time information turned out to be missing; additionally, such synchronized clocks may change rate or leap in order to stay synchronized, which is disastrous for logging. So monotonic time is easy to record, but how do we convert that to a more usable global time? I suggest we extract the necessary information directly from the logged data. If your system synchronizes its time with UTC or GPS, this time information will eventually occur in the dump. We scan the dump looking for time synchronization messages. Having found one, we take the time and subtract the monotonic timestamp from it; then this difference can be applied across the whole log to determine the UTC/GPS time of any other logged frame. Additionally, as a fallback option the system that wrote the log file may inject additional UTC/GPS/whatever time records into the recorded log file by using one of the reserved metadata entry formats, so that if the logged system turned out to exchange no time-related information, it could still be extracted from these additional metadata entries. The worst special case is when the data log contains neither logged time information nor time metadata entries, in which case the corresponding time column should remain unpopulated unless the user enters the time difference manually.
1 Like
Does that also mean that the node can keep sending all the messages it used to sent while normally operating, while software updating too?
I will start to prototype on these suggestions and let you know.
The specification does not prohibit that so we should assume that it is possible. We can, however, detect when the update is over by looking at the field mode of the heartbeat message (which I forgot to mention earlier). While the update is in progress, mode is MODE_SOFTWARE_UPDATE; after completion it will be something else.
1 Like
I guess we can cram things in the same column and introduce some colouring or more hover-over details on the separate window (bottom-left, or at the bottom, like wireshark does it)? Maybe only colour the data in hex/ascii a certain colour content-wise but keep some colours for the standard features that are crammed in the same cell(s). Ex. src and dest macs are ALWAYS the same colour., can ID is always a different colour, etc. What do you think about this usability/colouring ideas? Also, what kind of command line and Yukon UI filters do you think make the cut as common use cases?
More on the extra “window”, what kind of details would you want this to contain? I guess it should be a ‘plaintext’ component that changes between any selected row. That could also include doing some processing to find extra missing parts of the messages. An extra ‘header’ part in this component could also act as a placeholder for the hover-over information that multipart column entries provide.
I think we should stick with this monotonic/relative time treatment and maybe introduce extra log metadata at the header of the file (I’m investigating in what extent this is possible // cancel that, plain txt files can not have header parts // I’m investigating this further) in order to keep the ability to process with standard tooling. That would require determining a merge policy for logs that have no matching metadata.
Yes, I think we could learn a thing or two from Wireshark since its UX is top notch in my opinion.
Semantic coloring is very important and it’s probably best to use it for the main data columns in the first order; “main data columns” being everything except the transport frame header because the user would usually not care about it since all of the relevant information would be readily available in the other columns in the parsed form. Off the top of my head, the old GUI tool applies the following coloring logic:
- Time column: the shade of gray indicates the amount of time elapsed from the previous frame (darker = higher interval). Allows the user to quickly find discontinuities in the traffic and non-uniform traffic load.
- The CAN ID column is colored in a shade of pink where the brightness is proportional to the priority of the frame. Seeing as there is no such column anymore we should probably add a dedicated one for priority, I am going to edit my previous post.
- Both data views (hex/ASCII) are colored according to the transfer ID. This helps the user visually distinguish frames belonging to different transfers, this is very important, this logic should be kept. We should take, say, the five least significant bits for color hash computation.
- The color hash of the source and destination node ID is computed directly from their values.
- The data type column is colored according to the data type name; this logic should be kept in Yukon but we should also include the major version number of the data type in the hash input since it affects compatibility.
Yukon should also color the data specifier; perhaps the service request/response indicator should be put into the same column with the service ID so that there would be one “data specifier” column for both message and service frames? So that if there is a message frame, the column would simply contain the subject ID; if there is a service frame, it would contain both the service ID and an indicator (some icon perhaps) whether it’s a request or response?
Umm. Say, something generic, like numerical ranges or exact values for numerical columns like port IDs or node IDs; wildcards for the data type name column? Nothing tricky comes to mind. At least we could start with that and then see if it should be extended.
Ideally we should be approaching the functionality of Wireshark. We need full transfer reconstruction based on the selected frame; as I described elsewhere, the old GUI tool does that by walking up and down the log from the selected frame, collecting other frames belonging to the same transfer and then deserializing them. I am not yet certain how are we going to implement that with PyUAVCAN but it shouldn’t be hard. It would also be awesome if we could quickly jump between requests and corresponding responses; like, if the user selects a frame belonging to a service response, it could say “take me to the request which triggered this response”, and vice versa. For displaying the deserialized transfer we could perhaps use your generic data structure display component, I recall we discussed this earlier (unless we agreed on the plain text option, can’t recall).
I added additional metadata formats into the tentative log file format description, particularly the time synchronization frame: https://docs.google.com/spreadsheets/d/1yP9zXChKTaIm92Bd60jgrOSwGIeXp-CO5tGyYcaBopg/edit

The recording system would inject these synchronization frames periodically to allow the parsing system to determine the time offset between monotonic time and TAI time. The TAI time then can be trivially converted into any other time format, such as the Unix time, GPS time, Gregorian date/time, or whatever needed. We should discuss the log format separately; perhaps we should start a separate megathread? This discussion would be out of place here.
(this response is a bit rushed, sorry; I just don’t want to accidentally delay your progress by delaying my answers)
1 Like
Just previous frame, meaning current frame index - 1 ?
Do we include the transfer id inside this column?
Do you have any recommendations for priority color? Not sure if you want this to be just text color or background color (hex and rgb values are supported):

[
{
"time": 123,
"transportHeader": "this for now",
"priority": "immediate",
"routeSpecifier": {
"source": 35,
"destination": 102
},
"dataSpecifier": {
"subjectId": 5,
"metadata": {
"name": "test",
"version": "1.0"
},
"transferId": 0
},
"dataHex": "cd 66 53 5c 5b 08 bf fa d4 45",
"dataAscii": "..sNip..aSXIIuoi..ofjX"
},
{
"time": 124,
"transportHeader": "different one",
"priority": "slow",
"routeSpecifier": {
"source": 35,
"destination": 102
},
"dataSpecifier": {
"serviceId": 30,
"selector": 19,
"metadata": {
"name": "othertest",
"version": "1.1"
},
"transferId": 2
},
"dataHex": "ab 56 78 5a 3b 08 00 ff f0 4c",
"dataAscii": "..sNip..aSXIIuoi..ofjX"
}
]
How’s that for a JSON representation of the general form? The transport header is going to be added after I lay down the basic structure of this.
Yes, that’s the point.
According to the data model, the transfer ID does not belong with the data specifier:

In the old GUI tool the transfer ID is not explicitly shown, but that is probably a mistake. Let’s have a separate column for it; I am going to edit my post above accordingly. Note that on CAN (both CAN 2.0 and FD) the transfer ID wraps around 32; on other transports it grows continuously (the background and motivation are explained in the alternative transports post).
I hear that the jet palette is out of fashion now? If not, then let’s just use it. Otherwise whatever you find appropriate.
Both. I suggest they both should have the same hue but different lightness so that the background is light and the text color is dark:
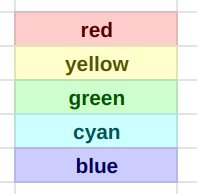
Coloring just the text seems insufficient because the color becomes barely distinguishable against the white background.
At a first glance it’s sensible except that you can’t say just “time”; it is insufficient because there are many incompatible ways of timekeeping. The timestamp should be converted into other time systems by the backend so the JSON model should account for that (so it’s not just “time”, it should be at least monotonic time (always available), TAI time (optional), and application-specific time (optional); the frontend can convert from that into appropriate formats). Also the transfer ID is misplaced but I wrote about that already.
1 Like
How do you want to calculate this?
Go here: Colors HSL
We can maybe use hsl(0, 0%, 0~40%) to calculate that. What’s the maximum (or clamp point) for the monotonic time difference expected? (I guess one second)
Same for that, maybe hsl(298, 87%, 0~40%), with white? text. Again, what’s the max canid expected?
I’m open to different color calculation ideas.
That being the previous colour snippet you have posted?
In what sense, too?
Same. I guess we can chat about these colourings on the devcall.
The jetpack palette seems good. Here are my color choices, in no particular order:

Now that the colors are supposedly out of the way:
The variance on these is huge. A couple of digits for the can frame, much more data for the IEEE & UDP frames. We can surely crame these on a single column, but if there are a few UDP frames present between CAN ones, the view will get messy: the column will get wide (or tall) in order to fit the other headers and will occupy much more space.
My idea is to either enforce single-line rows, where horizontal scrolling is enabled, or, limit the width of the specific column: CAN IDs and flags (smallest size) are shown properly, other headers occupy more vertical space.
I guess the frontend is supposed to heuristically determine whether the frame is can, UDP or IEE by querying for ‘rsss indicator’, ‘destination endpoint’ accordingly. If RSSS is present => IEEE. Else, if destination endpoint present => UDP. Finally classify CAN frame. These are for the JSON transport layer.
Yes, as discussed at the call, it’s one second.
In the original GUI tool only the priority was considered for coloring, so the range was [0, 31] (there are more priority levels in UAVCAN v0). In Yukon we’re going to have a separate column for the priority so the color dimension for the transport header will be freed up, meaning that we could use color to indicate the transport protocol. Does this seem sensible? This contradicts what I wrote earlier but we just added the priority column so things are different now.
So originally it was pretty haphazard: there were individual hash functions for different columns and the time column was limited to shades of gray which was unlike the others. How about in Yukon we do it more uniformly: define a general mapping of the form (value, lower_bound, upper_bound) --> color, then use it for every column? The color palette would be jet, but it would be trivial to make it changeable.
Priority, in particular, should be colored so that the high priority values would be on the red side of the jet palette and low priorities would be on the blue side. This makes intuitive sense: hot=urgent, blue=not so much.
So, to recap, the input of the color function per column would be roughly as follows (shown in bold):
- monotonic timestamp – time since previous frame clamped with [0, 1] seconds
- UTC or local timestamp (see below) – same as monotonic?
- transport frame header – transport protocol (for example, CAN - 0, UDP - 1, IEEE 802.15.4 - 2, etc.)
- priority level name per the spec (exceptional, immediate, fast, high, nominal, low, slow, optional) – mnemonic priority number, where high priority - red, low - blue
- route specifier:
- source node ID – node ID (see notes below)
- destination node ID (empty for broadcast) – node ID; white for broadcast
- data specifier:
- if message: subject ID – subject ID (see notes below)
- if service call: service ID and request/response selector – service ID (see notes below); not sure how to reflect request/response in the color, will need to test
- data type name and version (the mapping from subject/service ID is to be defined by the user or auto-deduced by parsing the logs) – some simple hash of the data type name and the major version number (see notes below)
- transfer ID – about ~8 (5 for CAN) least significant bits of the transfer ID (256 colors)
- data in hex – same as transfer ID
- data in ASCII – same as transfer ID
The reason we’re defining the color of data columns as a function of transfer ID is because it helps the user to visually relate data blocks spread over multiple frames in multi-frame transfers. Consider this example (this screenshot is from a coworker who was actually debugging stuff, so it’s very empirical):
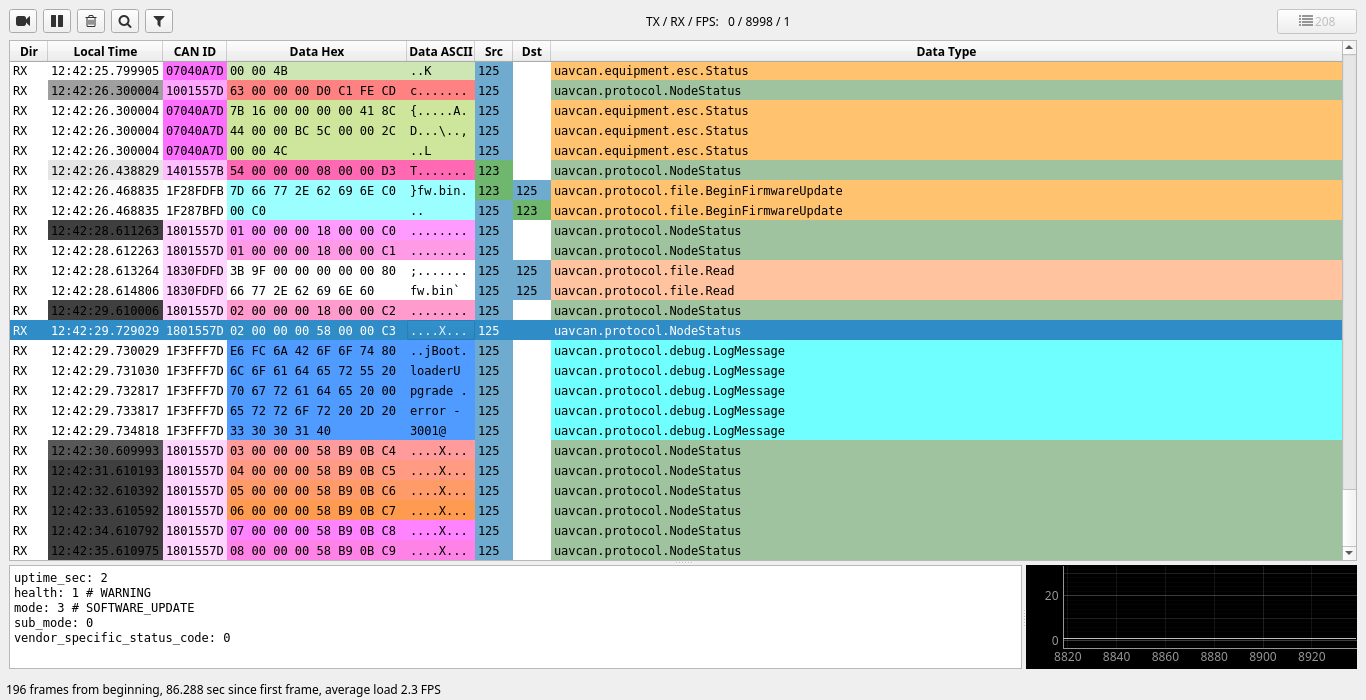
You can immediately see how the payload fragments should be grouped together because of the coloring: same color = same transfer = same data object. Of course there may be collisions since the space of unique transfers is enormous yet we only have a handful of distinct colors but they are rare.
From my experience with the old GUI tool I would say that a decent display provided, a regular human can more or less comfortably distinguish a few hundred of different shades.
Consider the case of subject ID, service ID, node ID, and the data type hash: a naive solution would be to feed the value to the color mapping function using the valid range of the value as the input bounds; e.g., for subject ID the range would be [0, 32767]. This would work, but the color difference between adjacent values would be indistinguishable to the human eye and/or some computer displays. Here is a 15-bit palette for reference; due to the large color space, it looks more or less smooth which is undesirable for us (e.g., subject IDs 32741 and 32742 would be virtually indistinguishable):

We could improve this by relying on the fact that for any given parameter majority of the systems will utilize only a tiny fraction of the state space, so instead of having, say, 32768 possible colors we would limit the space by the actual number of distinct values used in the current system. We could do that by defining an intermediate mapping as follows: suppose the system utilizes N distinct values; we collect them into an ordered set (the set being continuously updated at runtime). The index of a given value in the set becomes the value fed into the color mapping function. (If you want more background, this is a form of variable-length encoding, like Huffman codes; same principles are used in lossless data compression algorithms.)
Whatever you find appropriate. This seems sensible but it’s hard to pick the best approach without testing first.
I made a typo in the post you’re referring to, it’s supposed to be RSSI (received signal strength indicator) not RSSS. The transport type information should be communicated explicitly rather than deduced from available fields, otherwise future extensions would be painful.
As I sat down to write an abstract for the upcoming presentation, I had to take a broad look at what we are doing here. The broad look revealed (among other things) that we might be heading towards an undesirable duplication of effort on the front of the transport data logging feature. It could be that in the future (in fact, I would say in the very near future) we may want to define a yet another (very trivial) experimental transport protocol for point-to-point raw serial links like UART/RS-232/RS-485/USB-CDC-ACM (which would be close to what they do with DDS-RTPS out there). A plain serial link is similar in terms of data layout to the log files I’ve been talking about in this thread so we could avoid redundant efforts by defining a serial transport first and then using it for transport log storage on disk. The serial transport could be supremely simple; say, this trivial header format comes to mind immediately:
uint8 version ~ 0
uint8 priority # Like IEEE 802.15.4: bits 7..5 - priority
uint16 source node ID # 0xFFFF = anonymous
uint16 destination node ID # 0xFFFF = broadcast
uint16 data specifier # Like IEEE 802.15.4: subject ID or service ID + request indicator
uint64 transfer ID
uint64 compact data type ID
uint32 frame index EOT # Like IEEE 802.15.4: MSB set in the last frame, cleared otherwise
uint8[] payload
We could then define a new union data type in the standard data type set that would encapsulate transport-specific frame data. The resulting structure would be very simple thanks to its recursive dependency on itself: serial transport frames stored on disk would contain transfers containing serialized representation of messages containing the logged transport-specific frames. I am going to expand on this idea someday later.
Hello. This thread is really long … and I’m not sure exactly what was done. On my side what I’m currently working on PURE JAVASCRIPT code in the following projects (I’m only allowed to put 2 links because I’m a new user so can not point to all the git sorry I had to remove most of them).
- a way to convert DSLD to json : github.com/octanis-instruments/uavcan
- convert JSON to binary and reverse using the json definitions (parser and serializer)
- convert binary to frames and reverse and check the CRC
- emit events of kind ‘frame’ and ‘data’
- graphical interface: https://loradb.org/build/ (I need to learn how to use reactjs for some other projects)
- slcan adapter
- a node server for the events
- CRC check of uavcan
Everything is a still a little bit messy as we started to do those things only 1 month ago but our goal is to have UAVCAN. Our goal is to easily build graphical interface for scientific instruments based on nodejs / browser on RPi and without requirements for python.
Please feel free to take any part you like (everything is MIT) or make pull request on those projects. We also publish the finished packages on npm (uavcan, crc-can (bad name), slcan)
The plans for today is to have all the constants in the json definition and improve the react graphical interface to start to work on forms in which user can create data based on json datatype definition (via json schema)
1 Like
Thank you for the elaboration, Luc. Would you consider moving your JS implementation under the UAVCAN org on GitHub once it’s in a usable state? I am assuming here that you are planning to add support for UAVCAN v1.
Our goals here are slightly different as we are building a comprehensive diagnostic tool capable of supporting multiple transports, data logging & analysis (eventually), custom user interfaces, and many other things of which you have probably already read in the other thread GUI Tool – Next Generation.
Sorry about that, I have just tweaked the forum settings to prevent that.
Hi guys, I apologise for my absence but June is my exams period on university.
@lpatiny I took a look on the link you posted on the other thread, is there a reason minified code is all over the place? I could not comprehend it much. What I understood is that you are using electron. There is nothing wrong with this technology, but the UAVCAN server (as discussed previously), needs to be as realtime as possible, that’s why we decided to go with pyuavcan. Data is exposed over a rest api (docs here ) and the frontend is served via a Vue app.
Here’s a list of things that are already completed:
- node list, bus health status, server (backend status)
- node details & register viewer
- global register viewer & batch register updater (that includes form generation and validation through dsdl)
- SSE integration with our global state (vuex) when needed, in order to auto-update
We are now working on the raw data logger (think of wireshark for uavcan).
Planned:
- Subscriber
- Plotter (already designed, I think you could be interested to work on this part: it’s essentially extensible and configurable live plotting of specific data values)
Here are some articles I have posted regarding internals of Yukon/frontend:
https://medium.com/js-dojo/integrating-server-sent-events-with-vuex-9de7c0dfb3f3
https://medium.com/js-dojo/vuex-tip-error-handling-on-actions-ee286ed28df4
https://medium.com/js-dojo/javascript-best-practises-strongly-typed-routes-a6151883794
1 Like