Does being able to POST new configuration and restart yukon backend sound like a new idea?
I’d much prefer to have some database of a kind and add the ability to export data as log files or over json on demand, but let’s postpone that part till the other parts are in a more complete state.
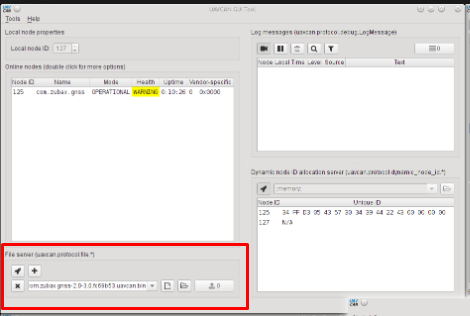
What’s the purpose of the file server on the old gui_tool?
I think the rest api interface is close to it’s final state: swagger link
Sure, but we don’t need to restart the whole backend. We just need to instantiate a new pyuavcan.Node and destroy the old one. We may even keep the interfaces running, but I am not sure (I’m yet to get to that part).
We need the file server for firmware updates:
Which reminds me that if the server is running on a different machine, the user should be able to somehow upload the file to the server via the GUI.
The file server may be useful by itself irrespective of the firmware update feature.
Another question: Type info caching during development of new types. If someone is going to use Yukon while developing new uavcan types at the same time, caching should be done on the browser’s cache that can be easily cleaned-on-refresh (example, on chrome: ctrl+shift+r / hard reload)?
Instead, we can always schedule type updates in the background, using types that exist in the cache and re-pulling everything from the server. That sounds like a bad idea and does not add much to the UX. Perhaps we can add some Cache-Control headers on the server-side with a variable ttl for each type: Practically infinite for UAVCAN public regulated ones, no caching for ones that are under some special dev folder (or if the folder contains a .nocache file?), a month or a day for other private unregulated ones.
Both parts of Yukon are probably going to run in the same machine while doing development, it should be pretty easy to just directory junction the paths that the backend is going to look at for the type info.
I don’t know what would be the best strategy. I think we can safely rely on the browser’s cache as you described in the beginning of your post, it seems sensible.
I don’t think it’s a sensible idea to require specific directory names or files, because due to the nature of DSDL it is expected that stable types will be sharing directories with unstable ones. You can always determine whether a data type is stable (i.e., safe to cache) by looking at its major version number: zero means unstable (don’t cache or use a low expiration timeout), anything >0 means stable (safe to cache forever or (better) until restart).
@Zarkopafilis I couldn’t run the changes from your pull request locally because the module @/Router is missing:
ERROR Failed to compile with 2 errors
This dependency was not found:
* @/Router in ./src/main.js, ./node_modules/babel-loader/lib!./node_modules/vue-loader/lib/selector.js?type=script&index=0!./src/App.vue
To install it, you can run: npm install --save @/Router
^C
✘-INT ~/uavcan/Yukon/frontend [:4d5c7aa|✚ 2]
21:54 $ npm install --save @/Router
npm ERR! code ENOLOCAL
npm ERR! Could not install from "@/Router" as it does not contain a package.json file.
This thread is not the right place for this post, but I couldn’t comment on the pull request because GitHub is malfunctioning (it’s weird, I click the “Comment” button and my text just disappears, come on Microsoft!).
@pavel.kirienko The idea for the streaming approach is as follows:
Now that vuex is inside the project, we have enabled a state management system that is accessible from outside of the component hierarchy scope, for all of the app’s lifetime. This enables us to initiate a websocket connection on the background, which update’s the state, with that being decoupled from each component.
This kind of websocket connectivity should be fire-and-forget on the backend side.
For example, on the homescreen part, when the app is firstly loaded, each component does a get request in order to load information about the server, the pnp table and the node list.
Using websockets, these can then be updated on the background even when the user is on a different tab. Support for each and every component is not required. For example, we can only implement this functionality for stuff like the node list and the plug and play.
I’m investigating possible architectures and writing tests.
On the python side of parts, you just add connections on to a set and then, on each event, you broadcast updates to each and every connection.
On the js side of parts, you just use an EventSource
I currently have experience with React Native, React, Redux, and Sagas. I see that you decided to use Vue and Vuex. I can invest some time learning about Vue in order to help out.
I’m curious to know if you considered using GraphQL instead of REST for the API?
Hello. It’s very nice to see new people coming abroad. We evaluated React for the project and ended up using vue over it, due to licensing and slightly better developer experience.
Personally I have evaluated GraphQL as a solution for the project. The problems it’s designed to solve are:
Consuming data from multiple sources
Avoid the need of reconstructing (mapping) objects in the frontend
… through an extra layer of abstraction.
Any webapp of medium size is going to have some kind of relation projected over REST endpoints. That aside, you can tell by just looking specific components that ql is not going to provide significant advantage (look at the Global Register View for example – the mappings and computed properties are huge).
Same thing with the “simpler” components: The 4 ones that make up the homescreen, for example. Yes we could debate over doing 1 call over 4 ones (1 for each sub-component). The 2 ones are really a couple of bytes and merging the other 2 would not make such difference. It would also make it a bit harder to separate concerns between components, require the logic of “splitting” the response inside the vuex/actions in order to update the correct module’s state parts.
I’m still open to using it if you find a proper use case: But for now, I see no valid one.
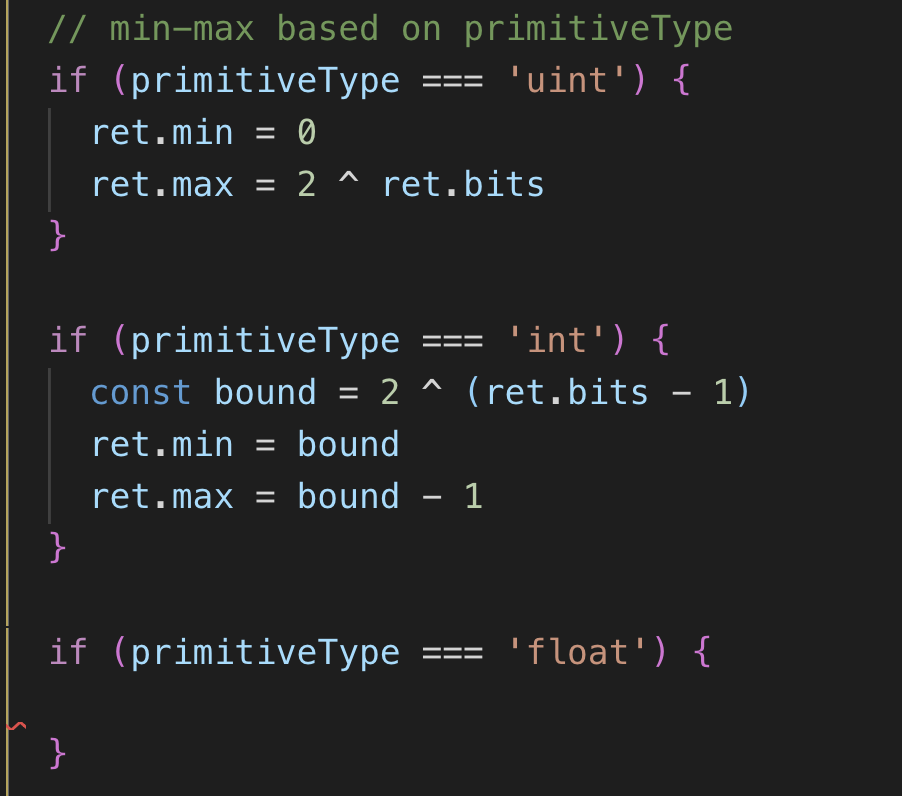
I unsure of what float format you are using. Do you have some spec or a formula that I can swiftly calculate min and max number for floats? (JS has only got a ‘number’ data type, per IEEE 754.
You seem to be missing a minus-one in the uint case. The upper boundary (assuming that it is inclusive) should be 2 ^ ret.bits - 1. In the int case, the lower boundary should be negated.
For floats we use three formats defined in IEEE 754: binary16, binary32, and binary64. Their maximum values are defined as follows:
where frac constructs a rational number for exact computation; if you don’t require exactness, feel free to omit it.
The minimum values can be found by negating the maximums.
I am wondering though, would it not be easier to just obtain type information from PyDSDL instead of computing everything in JS? Just asking.
It’s just for computing some min/max stuff for form generation/input validation. We can swap it out if it turns to be a problem.
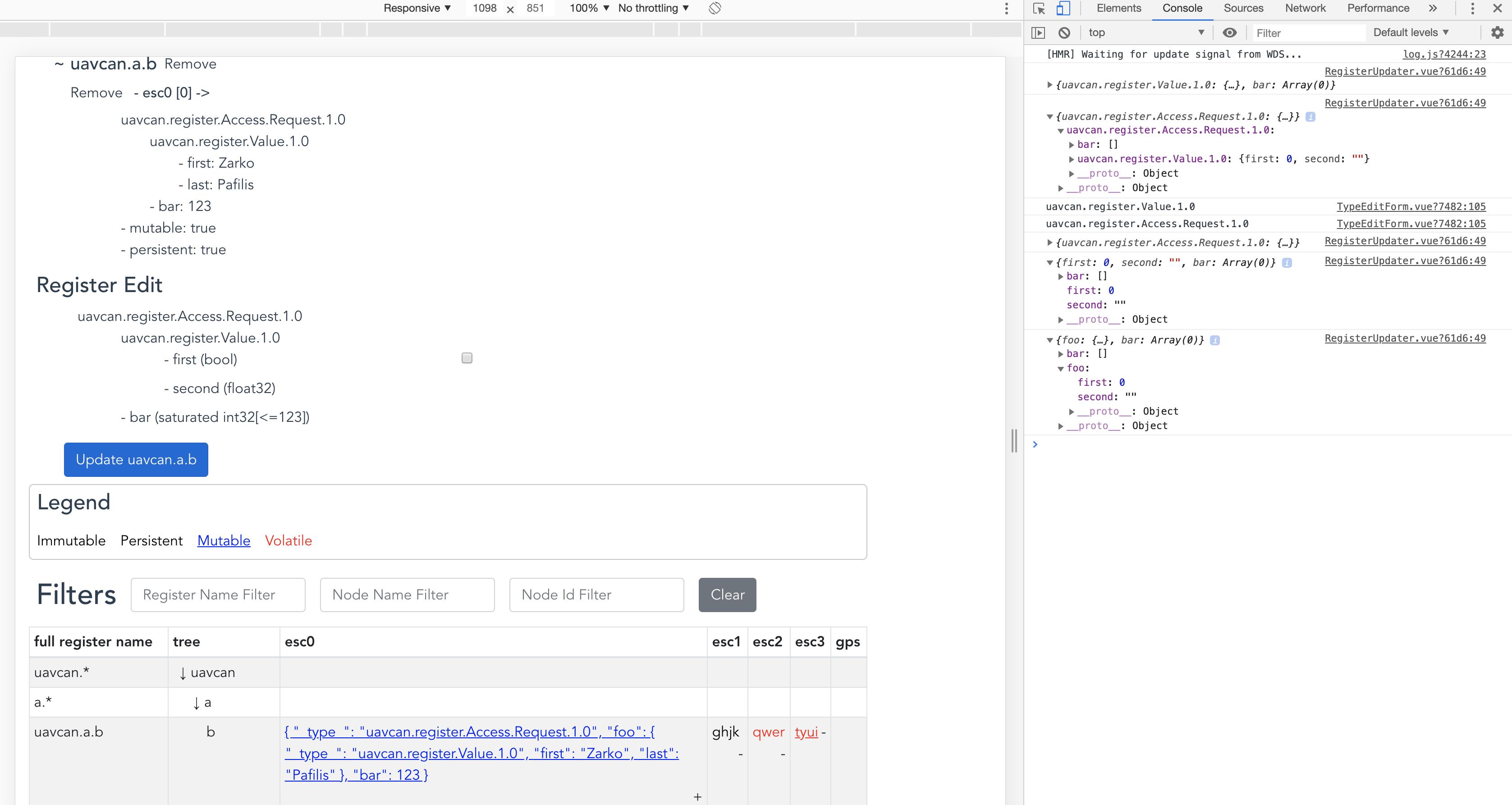
GRV is progressing fast, I guess I am adding a hover-over to view full tree of each register.
Does a click-register-truncated-value-to-add-to-workset ux sound good?
Hey Luis, unless @Zarkopafilis has something in mind for you to help him with, may I suggest you to contribute to PyUAVCAN instead? I am currently at the point where I need the media drivers for SLCAN, SocketCAN, and Python-CAN implemented. The new library has nothing in common with the old one (it actually has an architecture, for example) so the old drivers can’t be directly reused. If you have experience with asynchronous network programming, we could also use help with the socket driver for the UDP transport. I think at this point the architecture of the transport layer seems more or less solid so it should be safe to proceed with transport-specific implementations.
There is a plethora of things I could get some help with too. Here are some
Implement the subscriber widget with logging
Integrate existing parts with server event sourcing
Implement plotter
Add more functionality in general
I would advise you to look into this thread from start till now, so that you get some insights on the design choices and interactions. If you have questions please post them here or on the corresponding GitHub PRs.
As you can see I’ve finished the reconstruction of each type, errors and whatever we’ve ever chat about.
@pavel.kirienko the actual updating of the registers remains stubbed, as I would like to confirm how we are going to approach that. Do you want to have the frontend perform a request on the server with the register name and target node ids, letting the backend iterate over each node and update it with the values, or the frontend to perform 1 request per node targeted ?
I’d opt for the first choice, but we can maybe design this a better way if retrying only failed registers is required (I don’t think it matters that much though, because it wouldn’t take that much to update the registers on all the selected nodes again - as a retry - with updated values). A simple error message or list of nodes that were not updated / along with a fail reason (for the first failure, or for all the failures, or for 5 consecutive register update failures // I don’t know what else).
What’s your opinion on that?
UI/UX, styling and layout will be improved as soon as the basic functionality is complete, of course.
Design considerations regarding tracking state updates. The state updates I am referring to is not at all realtime:
Node Software Update %
Node Restart
Register Update Progress
In general actions that are not immediately applied
Ideas so far:
On the specific NodeDetail widget, Add a progress bar at the top, signifying specific node’s firmware update/restart status
On the HomeScreen, show a more compact version of said widget, once for each node undergoing procedures.
As I said on the previous post, in possible register update failure, how is the error treated ? Possible solutions would be to show “retry” buttons per node/register pair that failed, retry everything, remove sucessfully changed registers from the new temporary workset.
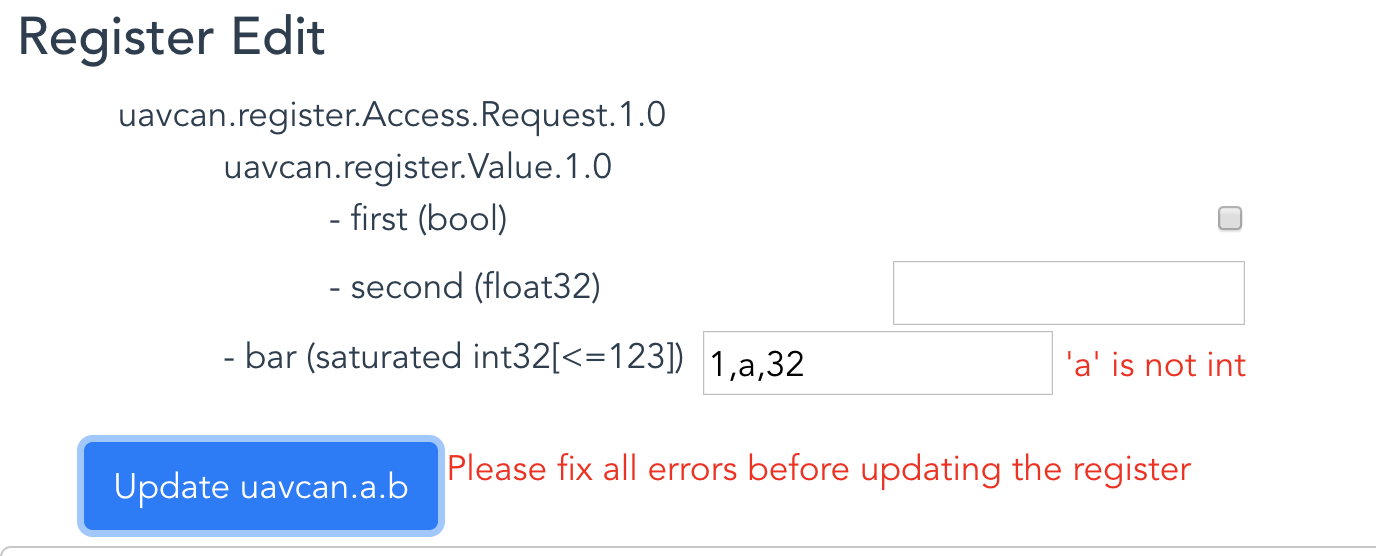
Do you want to automatically inject type value input fields with the provided value of each type? It could have some optional “reset to defaults” “clear” “reset to original value(s)” “set min” “set max”, but that would require special handling due to different nodes advertising different register parameterisation attribute values. Could be proven handy on single-node configuration
We need a way to show a truncated cell-fitting value for each register value
I need to come up with a usable and performant way to show expanded values on hover. Placing a hidden modal on each cell is has huge performance impact and a ‘dumb’ solution.
Worked on the UI a lot, added some confirmations for file uploads, node restarts, registers are now able to be added and removed, edited from the GRV.
My general opinion (feel free to challenge) is that we should strive to map UAVCAN exchanges to REST exchanges as precisely as possible, avoiding unnecessary aggregations or other deviations unless there are strong reasons to. For example, in the case of bus monitoring and message subscription, we have to use a different exchange logic on the REST side due to performance issues, so this would be an exception. I don’t foresee any performance-related issues in the GRV so that means that we should follow the exchange model of UAVCAN as closely as we can.
I think it does matter. The spec does not make assumptions about idempotency of register write operations, allowing applications much flexibility. If we follow the full-retry policy as you described, we would be implicitly assuming that register writes are idempotent. So I suggest we keep track of which ones have failed and then ask the user if we should retry. Would that be possible?
I would like to point out that the firmware update process is a bit hard to track because it inverts the control: once you requested a node to update its firmware, it takes over as the logical master of the following exchange:
A unit U (say, Yukon, or an autopilot, companion computer, whatever) calls uavcan.node.ExecuteCommand on a node N requesting it to update its software. The request contains the name of the image file.
The node N receives the request, sends a response, and (unless the request is for some reason denied) takes over from here. The unit U at this point is no longer in charge of the process.
The node N repeatedly requests uavcan.file.Read on the unit U using the file name supplied in the first step until the file is transferred.
The node N makes sure things are okay and starts executing the new software.
The inversion of control that occurs at the step 2 makes the progress tracking slightly non-trivial. You can easily detect only the beginning of the update process when the target node N responds with a confirmation saying that okay, it is going to update its firmware. Everything that follows can be observed only indirectly:
Monitor if the target node has restarted (but it’s not required to – theoretically, some nodes may implement some form of hot-swapping, updating themselves as they go).
Monitor the firmware file read requests. You can detect when the node whose ID matches N reads the specified firmware file. Knowing the size of the file you can determine how far along the update process the node is. However, it is not required to read the file sequentially, so this is a further complication.
Monitor diagnostic messages (uavcan.diagnostic.Record) from the node N. These are not formalized so hard to track automatically (that is, unless we’ve built in some kind of weak AI capability into Yukon which would interpret the meaning of log messages )
Would it not be easier to leave this to the user, at least for now? The user (being capable of abstract thinking and understanding, seeing as it’s likely to be a human being) should be able to deduce what’s happening by looking at the available controls & indicators.
As for the other undergoing procedures, I think we could generalize this into a simple display, like a set of tiny indicators, showing the currently pending service requests. Say, you send uavcan.node.ExecuteCommand to a node N, and its status display on Yukon lights up an indicator showing that the node is yet to send a response to such and such request. When the node responds, the indicator disappears. If the request has timed out, the indicator turns red or something. This feature is by no means critical and I weakly suggest to push back on this.
The format seems like a no-brainer but you never know. Basically I am proposing to take Popcop (which is just HLDC without the unnecessary fields), reserve the frame format code 128 for our logging purposes, and encode transport frames into Popcop using the structure outlined in the linked table. The format should be equally suitable both for storing data on-disk in log files and for transfering over the wire. Since every frame is stored as a separate atomic data unit, the user will be able to split and concatenate log files trivially by using cat and split directly. Thanks to the transparent channel offered by Popcop, frame boundaries can always be robustly located by looking for the byte 0x8E, since it is guaranteed to never occur inside a data record. The theoretical worst-case overhead would be just over 50% (that would be for a data frame consisting purely of 0x8E and/or 0x9E). Ordered log files can be queried for frames within a particular time interval in O(log n).

 )
)