I would say, anything more than 4 levels would be impractical.
The use case when a user needs to bulk configure multiple nodes or compare their settings is very common in UAVCAN. I am not sure how it can be adequately supported with the old paradigm implemented in the UAVCAN GUI tool where the settings of each node were displayed in a separate window. The old GUI tool also permits the user to have multiple windows open, but that doesn’t really help; I think the old design was a mistake.
The exact user story of the new multi-node configuration tool still needs to be worked out. Perhaps the user should be allowed to pick which nodes among the available they want to configure, then the GUI will discover their registers and display them on the table?
Inline might work well for simple scalar types like booleans, integers, and floats. Strings and arrays will likely require a popup. Or we could use popup everywhere for consistency and simplicity reasons.
The screenshot which I posted above is of Zubax Kucher: https://github.com/Zubax/kucher. It supports array parameter editing by rendering them as text when the editor is invoked, and parsing the edited text array back into its internal representation when the user finishes their edits. This approach is probably suboptimal though.
We have to invoke one service request per parameter, the protocol does not support batch editing, so it makes sense to reflect this underlying model in the UI.
I think CSV should certainly be supported because it’s so ubiquitous. JSON would also be cool to have because it is well-supported by different software products, e.g., Wolfram Mathematica. The JSON schema should probably resemble the definition of the uavcan.register.Access data type.
So, the batch configure is supposed to happen on nodes of the same ‘type’? So, we are going to have let’s say 4 ESCs and display their setting ‘X’ on a single or 4 different rows, on the concurrent configuration tool?
The tree depth does not really matter that much, but I’m just asking for design considerations (inline margin-left’s would be dynamic based on depth, after all).
Shall I change the endpoints of the backend from /nodes/:nodeId/parameters/… to …/registers/… ? Also, on the register definition posted above, I see no min/max or default setting, just value. Are these obtained separately? (I have to update the current spec to match the extra timestamp, persistent/etc states.) Reading the values back on each request really helps for automatic error checking. Same thing for register type. Parameters had some real/integer/boolean type. Where are the register ones?
They don’t necessarily have to be of the same type; for example, many different nodes may have a register named can.bit_rate, for example. We are probably going to encourage node designers to follow particular register naming pattern to ensure good coherence between different vendors.
Yes. I should have been more explicit about that probably from the start. But then again, it’s explained in the current spec draft.
See the docs for uavcan.register.Access:
For example, suppose we have a register named uavcan.node_id. Its min, max, and default values will be contained inside three other registers named uavcan.node_id>, uavcan.node_id<, and uavcan.node_id=, respectively. These metadata registers do not need to be displayed for the user, since they can’t be changed anyway; they are to be used by the tool to figure out the relevant parameters of the target register. The Kucher application which I linked above deals with these metadata entries as follows (open the link please, the excerpt displayed on the forum is incomplete):
I’m sorry, I must have ended up reading some wrong version of the spec of the draft in the process.
Here’s what I’m thinking about, regarding the Register list and editing UI:
UI Ideas:
Mutable registers only, show as clickable (blue anchor tag).
Persistency / Volatility show up in a different column named ‘Lifetime’ (or recommend something better). - -
Clicking them pops up the register update UI, which performs the request and gets the returned value back. If the returned value matches the expected one, the register update process is completed sucessfully.
Regarding the concurrent node configure, maybe we can have a checkbox that switches the view of available registers: based on selected nodes and/or selected register names. For example, you can type in some regex to match the nodes, and/or some regex (or text) for the parameter you want to change. These filters run independently but result in a set of nodes and parameters that are shown: Of course, as an error prevention feature, only the nodes that have the parameter listed are being contacted through the API. We can have some extra check on the popup register edit window that selects nodes and upon the press of the ‘Update Register(s)’ button, shows which nodes failed to accept the changes (did not report back new value).
API json responses format questions:
What’s the format to expose each individual’s register details? For example, do we send a list out of all the register names existing? (That means, each client needs to parse each individual one by name, decide which have min/max/default values based on $name[ <|>|= ]) Instead, we can do that on the backend and send the response in the current-ish format, which contains all the information for one register-details object, including the min/max/default values. The second one is my preferred way, which is more user-friendly on the client consuming the API. This does not mean that you are prohibited from querying each parameter by name: If you specify a name that ends with ><=, other parameters of that register (ex. current value, or the other min/max/default ones) are not queried.
How are the Primitives going to be exposed as a register’s data type? Instead of providing an enum of possible data types, we could have a field showing it’s object type [scalar, array, empty, string, unstructured] and if that object type is scalar or array, we can have an extra item type [bit, int natural, real] as well as a bit length type (not for bits) [2~64].
If we’re going to aggregate registers by name, the columns will be used for the node dimension, so there won’t be any free columns left for mutability/volatility (and possibly other flags which we may add in the future). I would instead recommend to display flags in the same cell as the parameter value (together with other parameter metadata). Different parameters sharing the same name may be mutable on one node and immutable on other nodes.
From the above indirectly follows that we probably shouldn’t hide any registers unless the user explicitly requested that. For example, the set of filters that you described later might also include options for mutability and persistency.
Yes, this makes sense. It might also be useful to allow the user to multi-select several register cells on the same row and then click some button to bulk-edit them, but it can be done incrementally. Please keep in mind that in theory, some nodes may not support the standard service uavcan.node.GetInfo, which means that we won’t be able to know their names, and the only way to select them would be to specify their node ID manually. Although our experience with UAVCAN v0 seems to indicate that implementers tend to always support this service.
For example, a user may want to see registers that match the following filters:
the node name matches some_vendor.* (suppose this is a wildcard); this automatically removes all nodes whose name we don’t know, e.g. which do not support uavcan.node.GetInfo.
the register name matches uavcan.*.
show only persistent mutable registers (i.e., only configuration parameters).
Take my response with a grain of salt, but I would actually prefer the first way, because in that case you can implement the whole register thing without introducing any special logic on the backend side. You will merely need a generic service invocation API: the frontend tells the backend to invoke a service such-and-such on the node so-and-so; the backend does that and simply returns the response structure as-is. It’s up to you, but the first case seems simpler, provided that you are okay with implementing the register type checking and input validation on the frontend.
Maybe it’s better to find a generic way of representing DSDL objects in JSON, and then use that model everywhere, including the register management logic? I recall @scottdixon said that he made something to that end.
While we’re listing deficiencies: one problem with the old design is that the UI often becomes unresponsive when attached to a very busy system. Remember that some views will be dealing with things that can number in the many hundreds of thousands and that can change at very high frequencies. Because of this it’s essential to avoid creating performance bottlenecks across the REST interface. The UI must deal with paged views into large datasets and the python server must provide ways of coalescing high frequency events before updating the state of the UI.
Just to throw my random two cents in, using an abstract representation like JSON or msgpack would be great. The more you can leverage slow changing solid 3rd party components, the faster everything will go.
Also, the peek interaction would work nicely for things you only need to see rarely, like type or bit depth. There might be a way to expand that later if that’s useful.
That’s kindof what I mean, but how are you going to face the problem Pavel addressed: You might want to select an arbitrary number of parameters that accept the same data type and batch-edit them. I imagine some two-row UI: The top part contains the register tree view, with all the filtering, flags, etc and then on the bottom, is the ‘current register workset’ : the homogenous (same data type) selected registers to batch-edit along with their target nodes and some buttons: remove from the working set, batch update all, etc.
Individually editing by clicking an edit button on the tree or on the working set row below, can be like the vscode window, or inline, or with a popup. Batch editing would not need a popup since we have something showcasing what we are working with below.
EDIT: With many many nodes displayed, I’m not sure if it makes sense to have each one displayed on a separate column, but the batch editor is a must.
Filtering: The node list homepage is meant to be a very quick overview of what’s on the bus: filter supports regexes as well and matches against all the attributes of the current node list response [id, name, health, status, vendor code] and supports sorting based on these attributes, ascending or descending order.
On the batch register editor, I think it makes sense to change that a bit. Split the filter on flags and arbitrary text provided. The text matches by regex or by .contains() the register name. Aside from that, we can have flags like lifetime:PM (lifetime: persistent and mutable) or simply lt:P and other shortcuts like that to make this usable.
I’m not sure if it makes sense to keep the current ‘expanded’ node details UI I posted on github:
, as a means of quickly looking up parameters on a single node: I can add a filter and some auto refresh on a particular one, or all of them or whatever.
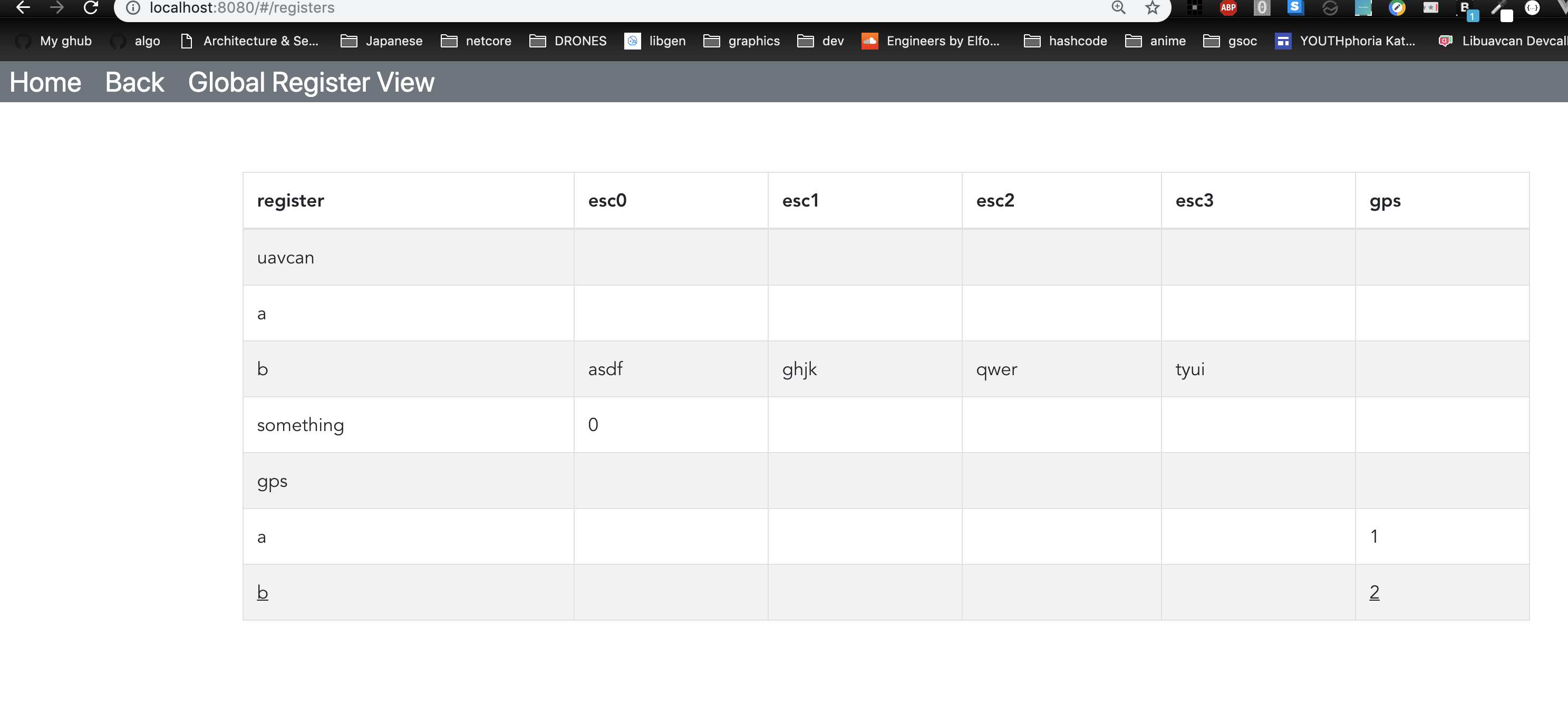
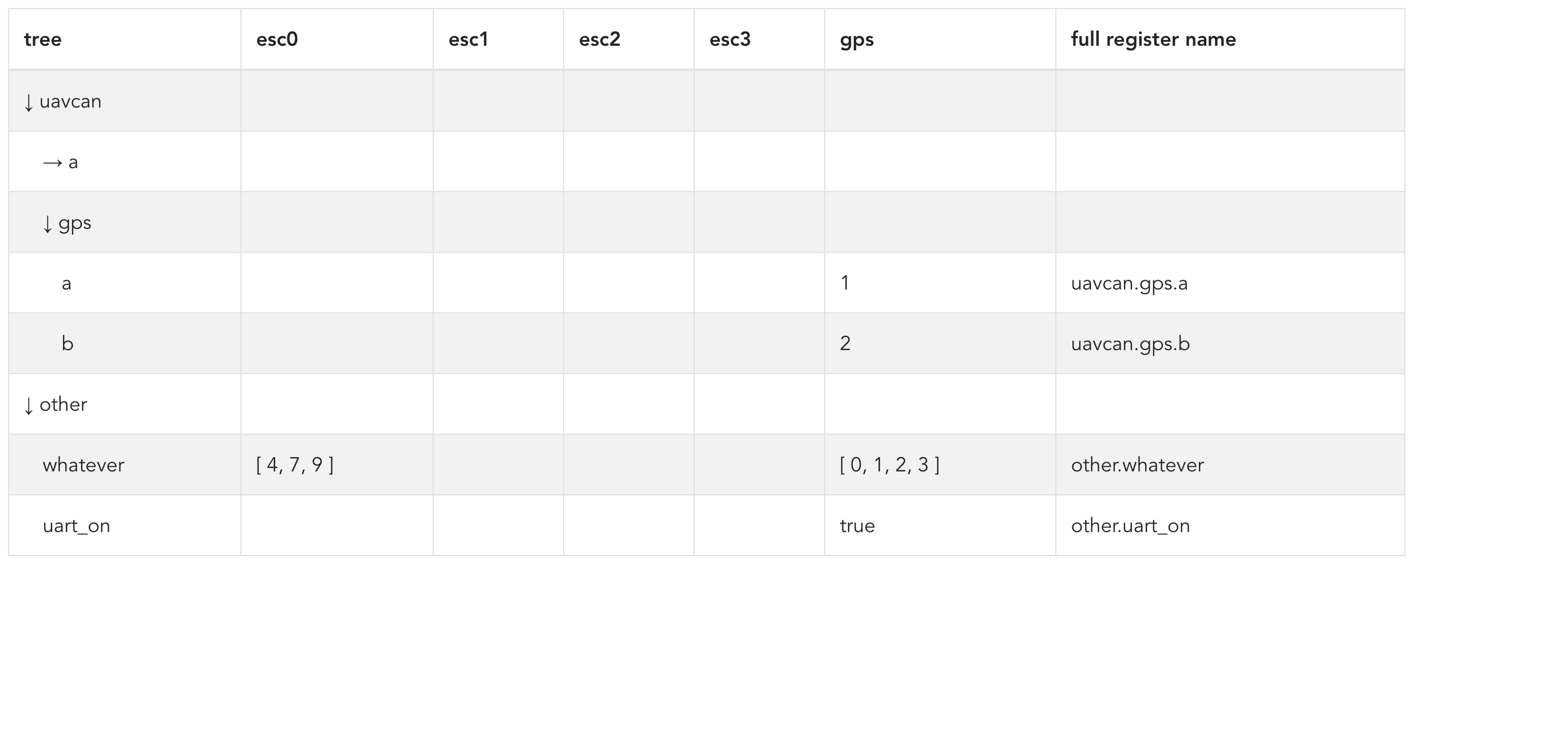
The crucial idea is that we take all registers from all nodes and join them into one view, so that the human developer can easily assess, compare, and modify all changeable and/or observable variables of the entire UAVCAN network from one place. There are huge possibilities for various semantic highlights and advanced features that can be added incrementally; for example, the user could ask the view to highlight rows that contain distinct (non-uniform) parameter values, or parameters that differ from their default values, etc.
Can we call this thing “Global Register View”?
There should be a way of viewing the node details (such as the CoA, version info, and so on) and issuing commands (reboot, shutdown, vendor-specific, etc). Viewing the node’s registers is optional since that function would overlap with the global register view. I’m not sure what’s the best way to implement that in the sense of UX.
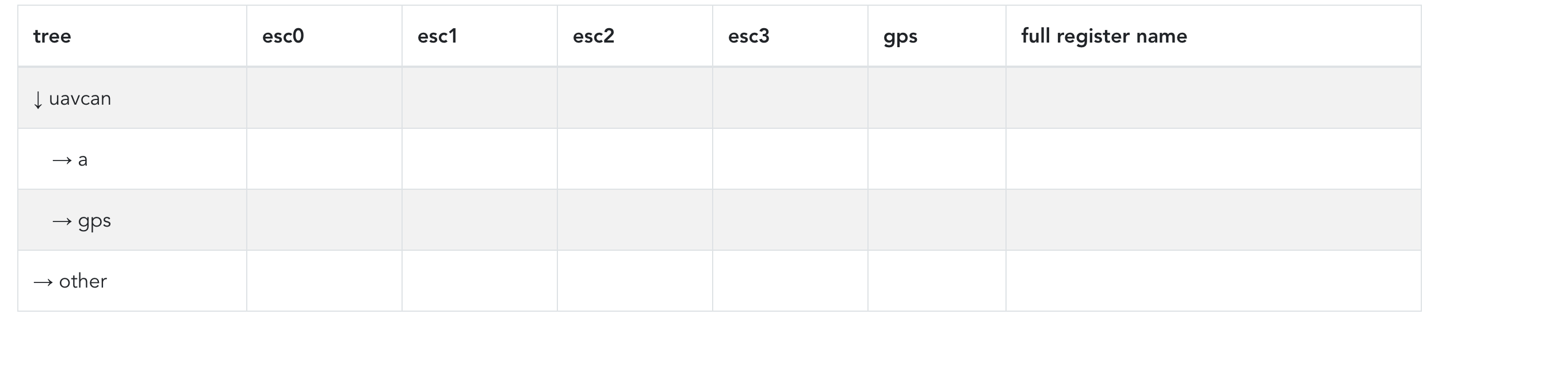
Here’s a first prototype of the global register view (it’s dynamic, meaning It’s being generated from the data model). Some things are missing, like collapse and expand
are missing, but I’m adding these as we speak.
How are we going to show current register mutability, persistency, value, it’s data type, min/max (if they exist)?
Do you have anything in mind for select for batch edit / edit individually controls? Buttons, colors, etc ?
Shall I add another panel on the bottom, showing the selected commands for batch editing ?
I am starting to think about the implementation of plotter tool too. We are probably going to use a simple websocket to stream new data to the frontend (or whatever consuming client). Is the UI-UX going to be the same as the old gui-tool , or are we going to drastically redesign it like the register view?
Start the global register view which is supposed to be a view on all the bus variability.
Postpone the design of the register types on the API side
Rename every ‘parameter’ thing to ‘register’
Things are in a highly WIP state, focus on prototyping, write tests upon each feature completion
Research a bit on third party component registration and dynamic integration
P.S. UAVCAN is the most important and challenging computer engineering thing I’ve messed with. Being part of the team feels great. Keep up the good work guys
The value could be displayed as-is on the rich cell. If the value doesn’t fit, it will have to be truncated; probably there should be a separate GUI element for displaying the value (also min/max/default) of the currently selected register in its unabridged form; for example, an array of 128 float16 values might be challenging to display adequately within the constraints of a single cell, but it should be fine to display in a larger element somewhere on the side or below the main register table. Min/max/default values could be either shown on the bottom row of the same rich cell, or they could be only displayed on the “detailed view element” as above. The flags (mutable vs immutable, persistent vs. volatile) could be either shown as icons (the way it is done in Kucher, as you can see on the screenshot I have posted) or they could be somehow reflected in the style of the rich cell.
The detailed register view should allow the user to select the preferred representation. For example, numerical arrays could be semantically lists or matrices.
Maybe the detailed view could also be somehow joined together with the batch editor? E.g., when the user selects multiple registers, their detailed views pop up below the table, allowing the user to somehow edit all of them at once (I have no idea what am I talking about).
Personally I don’t like GUI that hide information, so if there is a choice, I would lean on the side of showing as much information as we can at once; we shouldn’t require the user to click around to get what they want.
Notice that in order to know which registers are available on a given node, we have to discover them by calling uavcan.register.List. The discovery process is slow as there may be hundreds of registers per node and hundreds of nodes on the network. Luckily, the spec requires that the set of registers is to stay constant as long as a node is running, so we only need to load the register set once and then it can be cached (either on the front end or the back end) until the node is restarted. We could take further shortcuts and bind each cached set of registers with the node’s unique ID, so that when a node whose registers we queried earlier is reconnected/restarted, we could identify it by the UID and continue using its old registers while updating the cache in the background. This is something that can be implemented incrementally later though.
Could you incorporate the following use case please: the user selects a register and asks the GUI to poll it with a specified frequency while adding every returned value onto the plot? If the register is array-typed, there will be multiple lines/plots created, or the user could be explicitly asked which elements of the array to plot.
Let’s just say that I am personally very open to suggestions. Data visualization is hard; in the case of UAVCAN it is, I dare say, very hard. Whatever we end up with should be very extensible and generic so that we could support new use cases and new visualization strategies in the future.
There are known issues with the current plotting UX:
The data field selector is limited in functionality: it may suggest data elements which cannot be plotted (e.g., compound types), and it can only show suggestions for the first entered field; e.g. when you enter msg.voltage, you get a list of suggestions, but if you were to enter msg.voltage * msg.current, the list would fail to show up after voltage.
The correctness of the entered math expression is not validated; e.g. msg.temperature-273.15 is a valid expression, but msg.temperature- is not; the GUI would fail to warn you in the latter case.
It is currently impossible to define plotting expressions that span across independent messages. For example, if you want to plot electrical power based on the voltage value from one message and a current value from another message, you’re out of luck.
It is currently impossible to make the plotting engine poll a specific service and plot a particular response field.
The set of available visualizations is limited. Ideally there should be a library of representations such as histograms, 3D plots, surface plots, etc. They can be very handy when working with complex systems, e.g. when tuning a set of sensorless FOC propeller drives. Currently we only support simple time-Y and X-Y plots.
Does it make sense to have editable registers show up as clickable? Clicking would mark them selected for batch editing, or present a tiny popup that selects either individual editing or add to batch edit queue? I’m asking this because it would make sense to have the value style (black text-blue clickable link) represent editability/mutability and then have something extra on the side to represent volatility / persistency (maybe we can change the text colour as well). If we are to have this on the side, it would make sense to only have an icon for the least common case (volatility-persistency), perhaps only showing it when the parameter is volatile (or persistent), to reduce clutter.
It makes sense caching this on the backend. Heck, we can even use some cache control headers to avoid extra un-needed transfers
I think we should indeed have some default truncated value length and some default representation, but we need to know first, how we are going to pass around primitive and composite types first (even custom ones).
On the bottom, I can show a non-truncated view for the selected parameter set and if homogenous, allow batch editing.
Filters: I add one for register names, one for node names, some toggles for register flags (mutability, persistency), right?
Plotter stuff:
We can even have this subscribe to a filtered (by regex) data stream and render everything with a different colour.
Yes, we have the dimensionality problem again, because we need a way to visualise whatever data is available. Some possible aggregations could be added as well: ex. render a vector3 as element1 + element2 + element3, or on individual axes (multiple dimensions), or as individual lines on the value-time plane.
Turing completeness could be very easy to add, as you can on the fly evaluate chunks of javascript code: HUZZAH : we can have people writing their own rendering logic, with a tiny API (if our small configurable set of actions are not sufficient)
Perhaps. I think you’re best equipped at the moment to make judgements of that kind because you have your UI in front of you and you can see what works and what doesn’t. Further, let me provide you with a few UAVCAN hardware units as soon as we have anything that runs UAVCAN v1.0 (that is still some months away though) so that you can test things seriously (please PM me your address). Mocks are helpful but they are never as helpful as real hardware.
Right, but please remember that some nodes may not have names, only node ID, so that should be filterable too.
If name is not found, then match against ID: does that make sense?
Or perhaps, in order for the UI not to be limiting, we can have it either as a separate id textfield to match against, or a name:input id:input on the same text field (At this point I’d say it makes sense to have 2 separate text fields).
I will PM my address as soon as the hardware is ready
Where is the ‘register working set’ supposed to be? (With the full data previews) and stuff? Ontop would make sense, because the size of the table would be huge in both dimensions. I don’t want this on a different tab, it would ruin the ux. Do you agree with that?
Nevermind the awful navigation bar on the top, thats not it’s final form. @scottdixon
I see you added navigation screen layout on github. I like that. Does anybody have some suggestion to make or shall I go ahead and prototype that navigation as well?





{kind=link}