Interface design guidelines
The realization that software is more difficult to develop than hardware is one of the most important lessons of the Apollo program. — Computers in Spaceflight: The NASA Experience [Allen Kent, James G. Williams]
The concept of data type is a cornerstone of Cyphal. The protocol can only deliver good results if the developer practices a disciplined approach to data type design. To paraphrase Brian Kernighan, the border between an “elegant and efficient design” and a “bloody mess” may be thin.
In this chapter, an interface is defined as a set of one or more data types describing the structure of data exchanged across networks combined with timing constraints and behavioral contracts. The exchange of structured data drives the behaviors of network participants based on the interfaces they support. To author data types and interfaces, Cyphal includes its own specialized interface definition language called DSDL. DSDL documents formally define the service contracts that participants of an intravehicular network agree to respect and the structure of the data these participants will exchange. Networks are core components of distributed systems where system functions are served and supported by the network participants (nodes).
This guide defines a disciplined interface design using the following five key ideas:
Acronym connoisseurs may appreciate that the list conveniently abbreviates to SSSSS.
These key ideas are not novel; rather, they are a hand-picked collection of well-known practices adapted specifically to Cyphal and put into concrete terms. These five key ideas can guide data type authors towards correct, consistent, maintainable, and useful designs.
Before we start, there are a couple of things the reader should know. First, those familiar with the experimental version of the Cyphal protocol (UAVCAN v0 or DroneCAN) will notice that much of the guidance in this document defines the original UAVCAN/DroneCAN set of interfaces as being flawed. If you are porting a system from UAVCAN/DroneCAN it is of particular importance that you use this guide to understand the deficiencies of those interfaces so you can avoid the mistakes made in their design. Also, all DSDL definitions should follow the rules provided in the Cyphal specification such as documentation and naming conventions. This guide augments the specification’s requirements with hard-won lessons from past mistakes. You are free to repeat these mistakes without violating the specification but we hope you won’t.
A given component of a distributed Cyphal-based computing system is said to provide service if it participates in the data exchange using a specific well-defined set of Cyphal data types following the formal requirements imposed by their definitions. Usually, this involves publishing messages of well-defined types carrying particular data at specific rates. Also, it may involve responding to Cyphal service requests as dictated by their data type definitions.
Similarly, a given component is said to consume service if it relies upon the formal contractual obligations upheld by a service provider as defined above. Usually, that involves subscribing to messages of a specific type or making calls (sending requests) to a specific Cyphal service.
There is an unfortunate linguistic complication in the fact that a service can mean both the type of Cyphal communication (as opposed to messages) and a higher-level architectural entity. In this piece, we’re mostly focused on the latter.
We understand service-orientation as the general method of designing distributed systems as opposed to the much narrower definition of SOA given by W3C. Under our model based on the definitions given by the CBDI Forum, service-orientation refers to the design process that values the following core principles:
-
Abstract – service consumer is shielded from the implementation details.
-
Consumer-focused – the design is driven by the needs of the service consumer rather than the constraints of the service provider.
-
Reusable – once defined, the service can be applied to related tasks whose context or implementation details may be different. Existing services can be composed to implement new behaviors.
-
Published contract – the service is defined by its published specification and not by the specifics of its implementation. The behaviors of the service provider and its consumers are driven by the formal contract defined by the service specification.
The proposed values may be considered to signify a departure from the conventional approaches practiced in the design of deeply embedded vehicular systems where tight optimization to the requirements of the specific environment at hand is prioritized. We propose that the rapid increase in the complexity of vehicular electronics renders such established approaches unfeasible. At the time of writing this piece, the field of distributed vehicular computing is undergoing a similar shift in the design mindset towards increased levels of abstraction that occurred in the general ICT domain almost two decades ago. The need for abstract interfaces that are reliable and time-predictable is the raison d’être of Cyphal.
We suggest that the system designer views the network as an integral part of the onboard vehicular intelligence rather than its facilitator. A node that requires a particular service is to reach the network itself, as opposed to any of its specific participants, for the fulfillment of the service. As cleverly formulated by Lars-Berno Fredriksson in his CanKingdom protocol specification, network participants are to serve the needs of the network (“module-serves-the-network”), and their knowledge of the network should be minimized. The network itself should be defined by the designer of the vehicular system, who is then to design and/or integrate the participants (nodes) that underpin the network so as to meet its requirements.
Per the above, it is a breach of abstraction if any particular participant knows more about the network than it absolutely requires to perform its duties. The approaches advocated here are often more demanding in terms of hardware resource utilization than specialized solutions, but this is a conscious trade-off to ensure maintainability and reduction of long-term technical debt in quickly evolving sophisticated systems.
In the case of data-centric services specifically, abstract and consumer-focused design implies that the service should provide (consume) processed information that is clean of any impertinent specifics of the implementation. For example, a sensor that estimates the pose of a body may be installed with a non-zero rotation and translation relative to the origin of the body frame. A naive design may provide the estimated pose of the sensor along with the rotation and translation of the sensor relative to the body frame. The correct design would provide the estimated pose of the body hiding the specifics of the sensor installation from the consumer.
A critical aspect of robust and maintainable service architecture is orthogonality:
Orthogonality is a system design property which guarantees that modifying the technical effect produced by a component of a system neither creates nor propagates side effects to other components of the system. Typically this is achieved through the separation of concerns and encapsulation, and it is essential for feasible and compact designs of complex systems. The emergent behavior of a system consisting of components should be controlled strictly by formal definitions of its logic and not by side effects resulting from poor integration, i.e., non-orthogonal design of modules and interfaces. Orthogonality reduces testing and development time because it is easier to verify designs that neither cause side effects nor depend on them. [Wikipedia]
As a design property, orthogonality applies to services, data types that define them, and the composition of data types themselves. In the context of software interfaces specifically, there is a concretization known as the Interface Segregation Principle. For example, in a control system, a particular physical process may be continuously assessed and controlled in a closed-loop. The relevant characteristics of the process expressed in terms of the DSDL type system are typically invariant to the particular role within the control loop where the types are employed. Imagine a vehicular position control loop where the current position estimate is reported over the subject E, and the target position being commanded over the subject T; by virtue of modeling the same physical quantity, both E and T can and should leverage the same data type. Excessive segmentation of the data space with specialized data types harms the composability of the resulting system, potentially nullifying the advantages of the distributed architecture.
As another example, imagine that a data type designer wishing to express the concept of an airspeed estimate crafted up the following definition:
uavcan.time.SynchronizedTimestamp.1.0 timestamp
uavcan.si.unit.length.Vector3.1.0 pitot_position
uint16 filter_delay_us # [microsecond]
uint64 error_count
uavcan.si.unit.velocity.Scalar.1.0 true_airspeed
uavcan.si.unit.velocity.Scalar.1.0 true_airspeed_raw
float32 true_airspeed_var # [(m/s)^2]
uavcan.si.unit.velocity.Scalar.1.0 indicated_airspeed
uavcan.si.unit.velocity.Scalar.1.0 indicated_airspeed_raw
float32 indicated_airspeed_var # [(m/s)^2]
uavcan.si.unit.pressure.Scalar.1.0 static_pressure
uavcan.si.sample.pressure.Scalar.1.0 static_pressure_raw
float32 static_pressure_var # [(Pa)^2]
uavcan.si.unit.temperature.Scalar.1.0 static_air_temperature
uavcan.si.unit.temperature.Scalar.1.0 device_temperature
(N.B.: in this chapter, we omit most comments from DSDL definitions for brevity. Per the advisory rules set forth in the specification, every data type definition should be the single point of trust for its users which defines every relevant aspect of the service contract. This requires that data types should be extensively documented in proses that are not shown here.)
While the definition appears to include every pertinent piece of data, its design is suboptimal because it violates the Interface Segregation Principle, forcing strong logical coupling of unrelated items which hurts the extensibility and composability of the resulting distributed data system. Being equipped with the knowledge that the fields filter_delay_us and error_count (whatever their purpose may be, it is irrelevant for this case study) are present for virtually all sensor feed types in the designed data system, we split the definition into several orthogonal constituents:
- True and indicated airspeed estimate with the timestamp (same type for both).
- Static outside air pressure estimate with the timestamp.
- Static outside air temperature with the timestamp.
- Device temperature with the timestamp.
- The generic sensor metadata: filter delay and error count with the timestamp.
- Pitot position (not timestamped because it is assumed to be constant).
resulting in the following set of orthogonal and composable definitions. First is the type for the true/indicated airspeed:
uavcan.time.SynchronizedTimestamp.1.0 timestamp
uavcan.si.unit.velocity.Scalar.1.0 airspeed
float32 airspeed_var # [(m/s)^2]
uavcan.si.unit.velocity.Scalar.1.0 airspeed_raw
Assuming here that the raw measurement is of less relevance than the error variance, we reorder them to facilitate structural subtyping, should that become necessary in the future. Depending on the specifics of the domain, the two airspeeds (indicated and true) may be further combined and published in one atomic entity over one subject instead of two (the dedicated timestamp fields will not be needed in this case):
uavcan.time.SynchronizedTimestamp.1.0 timestamp
Airspeed.1.0 indicated_airspeed
Airspeed.1.0 true_airspeed
Next is the static outside air pressure type:
uavcan.time.SynchronizedTimestamp.1.0 timestamp
uavcan.si.unit.pressure.Scalar.1.0 static_pressure
float32 static_pressure_var # [(Pa)^2]
uavcan.si.sample.pressure.Scalar.1.0 static_pressure_raw
The generic sensor metadata would take a dedicated type that is reusable with different sensors. If multiple sensor services (subject publications, to be specific) are fulfilled by the same node (the air data computer in this case), the node can (and should) avoid the extra workload and traffic of publishing the same metadata multiple times by using the same metadata subject for all estimation subjects:
uavcan.time.SynchronizedTimestamp.1.0 timestamp
uint16 max_filter_delay_us # [microsecond]
uint64 error_count
That’s it. We have split one large and non-composable subject into several smaller composable subjects based upon loosely coupled, function-orthogonal data type definitions. Now, you might exclaim here that we didn’t provide types for the device and outside air temperature; this is because their use is already covered by the standard type uavcan.si.sample.temperature.Scalar.1.0. Should it be necessary to extend the temperature types with additional data later (such as, for example, by adding the error variance), it is always possible to do so by defining a new type and switching to that without breaking backward compatibility thanks to the extensibility provisions. It’s desirable to keep things simple and generic until it’s proven than an extension is inevitable. Another missing bit is the pitot offset, but as you might have guessed already, the generic length type is already defined under uavcan.si as well.
The manifestation of orthogonality-related concerns at the type system level will be reviewed separately in the section on safe typing later; the current section is mostly focused on higher-level issues.
The last practical case study we review is the well-known hard disk drive (HDD) addressing interface. This example is probably irrelevant for vehicular systems, but by virtue of coming from a completely different domain, it allows one to have a fresh look at the problem with a clear eye.
A conventional HDD data storage device consists of several rotating disks (platters) coated with magnetic layers on both sides. On either side of each platter, there is a movable read/write magnetic head. In order to access a specific block of data on the disk, the disk controller selects a specific platter, moves the head to its specific track (referred to as cylinder, see diagram), and awaits until the platter, which is rotating at the fixed speed, reaches the angular position where the start of the desired sector is underneath the head:
Image by Henry Mühlpfordt, CC BY-SA 4.0
The first HDD designs, in the spirit of their time, were electronically very simple devices virtually devoid of processing capabilities. Such drives were controlled using a very simple command set that explicitly instructed the drive to select a particular cylinder (track), a specific head, and wait until the disk reaches the specified angular position before commencing the read/write transaction. The resulting addressing scheme was aptly named cylinder-head-sector or CHS.
Suppose we view the drive controller as a provider of the disk read-write service. The modern theory of distributed systems tells us that such design is deficient because it doesn’t meet the criteria of abstraction, consumer-focus, and reusability. The leaky abstraction spills out the details of the hard disk implementation which results in the high resistance to evolution (the implementation cannot be easily changed because the consumer is also aware of it). One can immediately see the first prospect to optimization in the fact that, given the constant angular rate, the linear velocity of the head relative to the platter surface changes linearly with the cylinder number, which means that at the fixed sector size, the write density is constrained by the selectivity of the head at the innermost sectors, whereas the outermost sectors remain heavily underutilized. Yet, under this addressing model, such optimization is not easily implementable. Changing the core principles of the storage device (such as switching to solid-state memory or networked storage) would also be difficult.
The shortcomings of the CHS system were certainly not from the lack of understanding of robust design principles by its authors, but rather a result of the constraints imposed by the extremely limited capabilities of the electronics of the past. Thankfully, modern distributed vehicular computing systems are not subjected to hard constraints on the amount of abstraction logic. Considering that along with the fact that vehicular computing can be complex and tends to evolve, optimizing intravehicular interfaces for the specifics of the task-at-hand would be a mistake.
Getting back to hard drives, future models quickly ran into the limitations of the CHS system and, being unable to simply swap out the implementation without breaking service contracts, resorted to emulation, where the disk controller would report a completely fictitious CHS configuration to the host, running a mapping logic internally. In the more distant future, the CHS system was replaced with the properly consumer-focused logical block addressing (LBA) interface which hid the implementation details of the storage system completely, simply exposing a contiguously numbered sequence of blocks.
Distributed services and their interfaces shape the design of the distributed system and define how one would think about it. The basic decisions and contracts put in place by an engineer who designed the services will guide the reasoning of engineers implementing them. A well-constructed service should be defined by the end goals it is intended to accomplish rather than by the means of accomplishing those goals; following this principle will also render the service composable and interoperable with other participants of the system. In many cases, it will lead to additional abstraction layers within service implementations (that one might misidentify as being superfluous) and less optimal resource utilization than an equivalent interface narrowly optimized for the particular case at hand. Such overheads should be recognized, accepted, and tolerated.
A practical question that may arise here in the context of subject-based services (dataflows), specifically, is: how does one split a complex-typed subject into several smaller subjects while retaining atomic data transactions? The answer is to rely on the timestamps, as is the common practice in certain high-level messaging frameworks. As required by the Cyphal timestamping specification, data instances pertaining to the same instance of time should bear identical timestamps, thus allowing the service consumer (subscriber) to match related data items and process them atomically. For more hands-on guidance on this, refer to the user documentation of your Cyphal implementation.
One comparatively less important aspect that comes up frequently is the representation of various low-level implementation-specific ancillary data for diagnostic and logging purposes. Naturally, the main functional services cannot be polluted with implementation details, as demonstrated above, yet it is often desirable to have access to the inner states for diagnostic and debugging purposes, sometimes even in a production system. For that, we recommend one of the following methods:
-
The recommended option for various numerical states or states that tend to update periodically is the standard register interface uavcan.register.Access. The vendor can expose arbitrary scalars, vectors, matrices, or strings as human-readable named variables that can be queried atomically at the consumer-defined rate (pull semantics). For example, a motor controller vendor could define a register motor.i_dq of type float32[2] containing the rotating system’s current vector components. The same interface is also used for modifying the node configuration parameters, assigning the port identifiers, and any other schemaless weakly-structured data.
-
For irregular events that should be reported using the push semantics (where the updates are provider-driven as opposed to consumer-driven) in a human-readable format, the standard log subject uavcan.diagnostic.Record should be used.
-
An equipment vendor may choose to define a vendor-specific data type for complex vendor-specific data.
To summarize this section:
-
Apply top-down, consumer-first design. Define services based on the addressed problem rather than the available means.
-
Define granular, composable services (dataflows). Many simple services based on a few abstract data types should be preferred over a few complex services based on specialized data types. Separate data pertaining to different processes or states. Separate data from metadata (sensor measurement/sensor state).
-
Design for the future. Do not shy away from abstraction, hiding the implementation details even if it may seem superfluous at first. Be visionary and don’t hesitate to trade-off performance gains for generality and clarity.
Our publication about idempotent interfaces and deterministic data loss mitigation shows that someone designing a mission-critical intravehicular network may benefit from unlearning some of the principles that are commonly found in general-purpose networked applications. Stateful communication is one such principle.
For the purposes of the following discussion, we will introduce a specific conceptual framework. The state of a process executed by a distributed system is understood as a point in an n-dimensional space where each dimension is mapped to one of the n process state variables. The process itself is then to be understood as the trajectory of the said point steered through the state space.
A distributed process is such a process whose state variables are controlled by different agents that interact through the network. To implement the correct state trajectory, the agents must ensure a consistent view of the involved process state variables.
An interface between the collaborating agents facilitating the distributed process is said to be stateful if the exchanged information omits some of the process state variables, thereby requiring the agents to rely on their own model of each other’s state instead of providing them with a direct view of it. The interface is said to be more stateful if it leaves out more state variables from the network exchange. Conversely, an interface that communicates (more) state variables explicitly is said to be (more) stateless.
In order to steer the state along the desired trajectory, all collaborating agents must share a consistent view of its variables. Failing that, a distortion of the trajectory will result, which we call a process failure.
A closely related concept is idempotence, which is applicable to interfaces in distributed systems.
Idempotence is the property of certain operations whereby they can be applied multiple times without changing the result beyond the initial application.
The proposed framework makes the following observations trivial:
- Stateful interfaces may be less demanding to the performance of the distributed system because they exchange less information between agents.
- Stateless interfaces are more robust against process failure resulting from the divergence of the collaborating agents.
- Systems based on stateless interfaces are easier to analyze because state variables are distributed among fewer agents.
- All fully stateless interfaces are idempotent.
Note that the service idempotency discussed here is not related to the temporal transfer redundancy (that is, intentionally repeated transfers) discussed in the article “Idempotent interfaces and deterministic data loss mitigation”. The article discusses the idempotency guarantees that are artificially emulated by the Cyphal transport layer with the help of the transfer-ID counters. Readers interested in the technical details are advised to consult with the Cyphal Specification. The summary is that Cyphal provides a hard guarantee (presuming that certain basic assumptions hold) that every transfer is received at most once, which allows the sending node to repeat transfers multiple times if it is expected that the network may lose some due to its known lack of reliability. This is proposed as an alternative to the traditional confirm-retry logic (e.g., TCP/IP, CAN, or DDS/RTPS model) that is more deterministic at the expense of certain new edge cases that must be considered.
Conventional, non-high-integrity applications, such as those found in the general ICT domain, are commonly designed with a completely different set of core design goals compared to high-integrity vehicular computing systems. As a result, interface design choices that are optimal in the former may be suboptimal for the latter. As the former field employs vastly more engineers than the latter and its discourse is far more extensive, we are dismayed to find that the mindset and practices that are poorly suited for the latter creep in there anyway.
A diligent engineer designing a Cyphal-based distributed vehicular computing system should strive to produce robust interfaces that are tolerant to a loss of state caused by restarting nodes, able to recover from transient failures with minimal intervention from other participants of the network, and are easy to verify and validate.
| Mode |
Possible advantages |
Likely disadvantages |
| Stateless |
Robustness, determinism |
Higher average-case resource utilization |
| Stateful |
Reduced average-case resource utilization |
State-space segmentation, complex failure modes, fragility |
Examples
Camera configuration
Consider the following educational example (it may not accurately reflect the specifics of production applications, but it illustrates the interface design principles). The vehicle is equipped with cameras that publish rectified 24-bit RGB888 frames using the following type:
uavcan.time.SynchronizedTimestamp.1.0 timestamp # Shutter timestamp.
uint16 IMAGE_WIDTH = 1280
uint16 IMAGE_HEIGHT = 800
uint8 BITS_PER_PIXEL = 24
uint8[IMAGE_WIDTH * IMAGE_HEIGHT * BITS_PER_PIXEL / 8] rectified_rgb888_pixels
The camera is self-triggered synchronously with the network time (relying on the network time synchronization service instead of a dedicated hardware trigger signal); runtime reconfiguration of the exposure and flash duration is supported for enhanced operational flexibility. A designer who failed to adopt the proper mindset of distributed stateless thinking might implement the reconfiguration logic via a dedicated Cyphal service type. In the following example, the configuration service provided by the camera accepts the desired configuration and returns the actually applied configuration that may differ due to rounding or auto-configuration:
uint8 frame_rate # [hertz] The desired triggering rate. Phase-locked to seconds.
uint8 FRAME_RATE_DISABLE = 0 # No triggering, camera disabled.
uint8 FRAME_RATE_MAX = 60
uint32[<=1] exposure_duration_us # [microsecond] Automatic exposure if unset.
uint32 EXPOSURE_DURATION_MIN_us = 10
uint32 EXPOSURE_DURATION_MAX_us = 200_000
uint32[<=1] flash_duration_us # [microsecond] Automatic flash if unset. Zero to disable.
uint32 FLASH_DURATION_MAX_us = 100_000
@assert _offset_ % 8 == {0}
---
uint32 exposure_duration_us # [microsecond] Adopted exposure duration.
uint32 flash_duration_us # [microsecond] Adopted flash duration.
While the described design may seem sensible at first, it is actually flawed because it requires the service consumers (i.e., subscribers to the camera frames) to make assumptions about the current configuration of the camera. The interface is prone to failure should the camera suffer a sudden loss of state – e.g., a power cycle, or a race condition when it is mistakenly reconfigured by another consumer. It is possible to mitigate this shortcoming by issuing the service calls periodically (thereby making the effects of a configuration loss contained by the next service call), but this would result in a non-idiomatic design because per the Cyphal specification, services are intended for inherently stateful low-level interactions. Replacing the service with two subjects instead – one for configuration input (modeled after the request schema) and one for the status (modeled after the response schema) – renders the interface decoupled from the implementation details (the consumer will not need to be aware of the node-ID of the camera) and more composable (multiple cameras can be subscribed to the same configuration subject for lockstep operation). The resulting definitions would be as follows:
# Camera configuration message type.
uint8 frame_rate # [hertz] The desired triggering rate. Phase-locked to seconds.
uint8 FRAME_RATE_DISABLE = 0 # No triggering, camera disabled.
uint8 FRAME_RATE_MAX = 60
uint32[<=1] exposure_duration_us # [microsecond] Automatic exposure if unset.
uint32 EXPOSURE_DURATION_MIN_us = 10
uint32 EXPOSURE_DURATION_MAX_us = 200_000
uint32[<=1] flash_duration_us # [microsecond] Automatic flash if unset. Zero to disable.
uint32 FLASH_DURATION_MAX_us = 100_000
@assert _offset_ % 8 == {0}
# Camera status message type.
uint32 exposure_duration_us # [microsecond] Adopted exposure duration.
uint32 flash_duration_us # [microsecond] Adopted flash duration.
BMS status
Suppose that the objective is to design a Cyphal interface to a BMS for the traction battery. The physical states managed by devices like BMS can be unambiguously segregated into two categories by the rate of their evolution: slow ones (like the battery capacity, state of health, number of charge cycles), and fast ones (like the available energy estimate, state of charge, temperature). Recognizing that the data exchange and processing resources of the network are finite, an engineer may segregate the Cyphal services offered by a BMS into two categories in a similar manner: high-frequency ones and their slow complements.
A naive design inspired by traditional client-server applications might be to define a status message (or several) carrying the high-rate data along with a certain flag that is raised whenever the slow states have changed, prompting the consumers to query the BMS node for the updated low-rate information. This design, however, is flawed due to its highly stateful nature and the obvious race condition.
An idiomatic design would define a dedicated secondary subject carrying the low-rate data where the messages would be published both at a fixed rate and additionally ad-hoc on change (possibly at a lower priority). Should it be deemed impractical to exchange such low-rate data periodically (e.g., due to the large amount of such optional data coupled with its low significance for most consumers), it is possible to publish a modification counter with a large overflow interval (or hash) that is updated whenever the low-rate optional data is changed, prompting the interested consumers to explicitly request the data (e.g., using the standard service uavcan.file.Read) while safeguarding them against race conditions.
Fail-operational systems
Interfaces to most industrial machines are designed with the presumption that the safest state is where the system is deactivated. This mindset is inadequate for those safety-critical applications where an unscheduled deactivation of the system (e.g., in the event of an emergency) may lead to drastic consequences. For example, any problem with a typical factory robot may be quickly contained by pressing the emergency stop button, whereas applying a similar failure handing policy to an aircraft engine may lead to a catastrophe.
The difference in the safety requirements motivates why the approach taken by the CANopen DS402 motor control profile that requires the service consumer to navigate through the complex state machine to launch the motor may not be applicable to the critical systems of an aircraft. The designer seeking to equip a propulsion controller with an arming switch must carefully evaluate the expansion of the state space of the resulting system – it is quite possible that the safety gains introduced by the arming logic may be outweighed by the undesirable effects of the increased complexity of the interface.
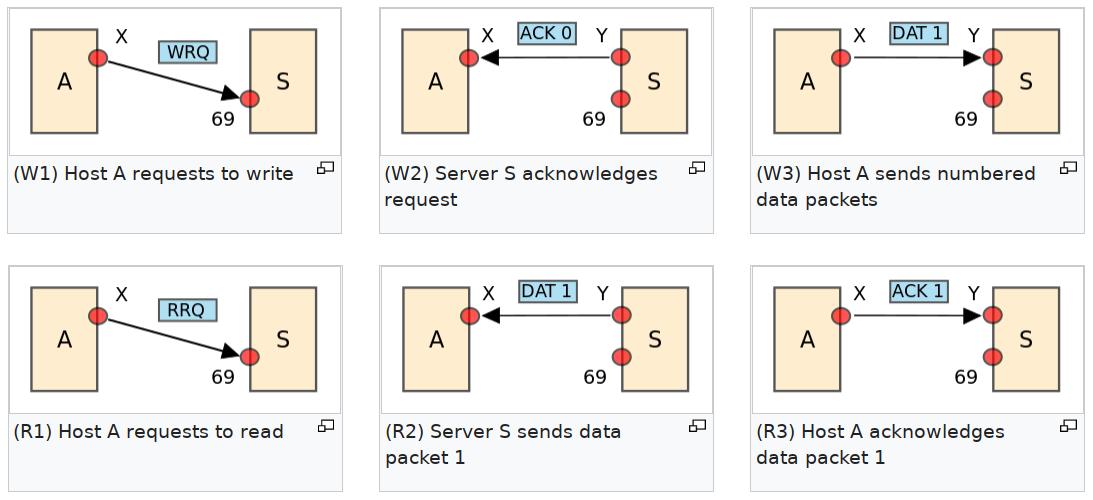
File transfer
TFTP is a simple file transfer protocol designed for conventional ICT applications. Its advantages include simplicity, efficiency, and low resource utilization. The disadvantage that is most relevant to the current discussion is its high dependence on the correct coordination of the communicating agents which results in fragility. The basic operating principle is summarized in the following diagram:
(Image adapted from Wikipedia)
The intended applications of TFTP can tolerate its low reliability. The danger here is that an engineer who is familiar with the typical design methods practiced in the general ICT industry might inadvertently carry over the accepted design trade-offs into a domain where they would yield deeply suboptimal results. A diligent engineer designing an intravehicular Cyphal-based network will always be aware of the different design objectives and will avoid the mindless transfer of ill-suited methods.
Consider the standard file transfer service built upon the types under the uavcan.file.* namespace. Responding to the different design goals, the Cyphal standard file transfer protocol is less efficient, but it is entirely stateless (excepting the optional soft states that may be leveraged by the implementations to improve the average-case performance). Cyphal file transfers are resilient against arbitrary disruption in communication and the involved network interactions are idempotent.
In the context of Cyphal service design, type safety is understood narrowly as the construction of interfaces that are robust against unintended misuse and that convey the intent of the designer clearly and unambiguously through the DSDL type system.
Previously we mentioned that the concept of orthogonality can manifest at the data type composition level. We can illustrate this with the following synthetic example of a hypothetical Cyphal service that provides a remote shell command execution capability:
uavcan.primitive.String.1.0 command
---
uavcan.primitive.String.1.0 output # Ignore if errored
uint32 status
uint32 STATUS_OK = 0
Suppose that the service contract dictates (this should be detailed in the DSDL comments but we take shortcuts for conciseness) that upon successful execution, the status should be zero and the output should contain, well, the output of the command, if any. In the event of an error, however, the output should be ignored and the status should be non-zero. This design is flawed, but before we turn to the fix, let’s consider a failed attempt at designing a (fictitious) actuator command type:
uint8 command_type
uint8 COMMAND_TYPE_FORCE = 0
uint8 COMMAND_TYPE_POSITION = 1
uint8 COMMAND_TYPE_RATIOMETRIC_POSITION = 2
float32 command
Both of the illustrated examples suffer from the same design issue: they fail to adequately express the semantics of the data through the type system, resulting in poor service design with an interface prone to accidental misuse. A diligent designer would notice that in the first example, unsuccessful execution renders the output redundant, and in the second example, the type of the command is a function of the command type selector. Expression of the data semantics through the type system results in fool-proof interfaces that force the user (and/or the programming language used to implement the logic, provided that its own type system is adequate) to avoid certain errors.
The corrected service design would make use of a disjoint union to express the mutually exclusive nature of the error and success cases:
uavcan.primitive.String.1.0 command # The request is unchanged.
---
@union # The response is a disjoint union.
uavcan.primitive.String.1.0 output # Success case.
uint32 error # Failure case.
The actuator command message would make use of the disjoint union to encode the different physical meaning of each option through the type system. Additionally, the decoupling of the command type from its meaning allows the designer to better express the ratiometric case:
@union # Three type-safe options: force, position, ratiometric_position
uavcan.si.unit.force.Scalar.1.0 force # Notice the types.
uavcan.si.unit.length.Scalar.1.0 position
int16 ratiometric_position
int16 RATIOMETRIC_POSITION_NEUTRAL = 0
int16 RATIOMETRIC_POSITION_MAX = 2 ** 15 - 1
int16 RATIOMETRIC_POSITION_MIN = -RATIOMETRIC_POSITION_MAX
As a rule of thumb, a well-typed interface is devoid of special values that modify the semantics of the variable and it does not rely on implicit typing where the meaning of a value is defined by another value. This may feel foreign to C programmers but adepts of the less type-challenged modern languages will feel at home. (N.B.: a careful reader will notice that the standard namespace uavcan.* contains a couple of data types that violate these principles; this is a known design deficiency that is left uncorrected for the sake of backward compatibility with UAVCAN/DroneCAN.)
DSDL supports structural subtyping that can be leveraged for building abstracted interfaces in the spirit of object-oriented programming where the generalized data is defined in the first fields of the schema and the specialized fields are added near the end. In some cases, this approach allows the data type author to uphold the interface segregation principle by providing a single abstract root type accompanied by concretized subtypes.
The aforementioned structural subtyping is facilitated by the so-called Implicit Truncation Rule. Together with its counterpart – the Implicit Zero Extension Rule – the two enable simple and straightforward means of data type evolution where existing types can be amended with new fields inserted at the end of the definition without breaking backward compatibility. Existing fields cannot be removed in general, but fixed-length fields can be replaced with voids if they are no longer relevant. For example:
# v1.0
float32 foo
float16[3] bar
float64 baz
# v1.1
float32 foo
void48 # We no longer need the bar.
float64 baz
# v1.2
float32 foo
void48
float64 baz
uint8[16] qux # New field.
If bar was a variable-length entity, such replacement would not be possible to do in a safe manner. The design of the extensibility features of DSDL attempts to offer an optimal balance between its capabilities and the simplicity of the implementation. Those seeking more background information about this will benefit from the knowledge that DSDL leverages a non-TLV non-self-describing binary serialization format as explained in the technical discussion in Data type extensibility and composition - #7 by pavel.kirienko.
If the scope of the changes to a data type cannot be accommodated by the available means of type extensibility, the designer should consider releasing a new major version of the type. This comes with the breakage of backward compatibility. If a soft transition to the new interface is desired, the affected services should be constructed with the support for both versions of the interface (the old and the new one) for the duration of the transitory period. Immediately upon the commencement of the transitory period the old data type definition should be annotated with a special directive @deprecated to signify its impending removal from the system.
Excepting certain uncommon special circumstances, all fields should be byte-aligned, as this allows the implementations to use drastically faster byte-level (de-)serialization routines as opposed to their slower bit-level counterparts. The data type designer should use the @assert _offset_ % 8 == {0} directive to statically prove that under all possible field layout configurations the fields are always aligned. When combined with the special variable _offset_, the assertion check directive can be used for validating complex properties of the layout, as shown in the following practical example of a data type that models a UDP/IP datagram:
uavcan.time.SynchronizedTimestamp.1.0 timestamp
void8
@assert _offset_ % 64 == {0}
# Ensure 64-bit alignment here.
Endpoint.0.1 source
Endpoint.0.1 destination
@assert _offset_ % 64 == {0}
# Likewise -- the endpoints are 64-bit aligned as well.
uint14 MTU = 1024 * 9 - 20 - 8
uint8[<=MTU] data
@assert _offset_ % 8 == {0}
# Whatever the payload size may be, the end offset is always byte-aligned.
There are more practical examples in the public regulated data type repository.
Since data type definitions establish formal service contracts, it is paramount to ensure that every definition contains a detailed and exhaustive service usage specification. As was said earlier, the examples given in this document lack such documentation for brevity, but for production types, this would be unacceptable. A data type definition is a single source of truth for the users and providers of the modeled service, and as such, its embedded documentation written as DSDL comments should provide every pertinent bit of information about it. Such documentation should never be kept separate from the data type definition because it creates the risk of divergence, and makes the definitions prone to misuse due to having to consult with several artificially separated sources instead of one.
Semantic segregation
This design aspect might not require a separate section since it is already covered by the principles of service-oriented design. However, the prevalence of poor design practices perpetuated by certain prior art made it necessary to warn the architects of the possible pitfalls here.
The basis of this discussion roots in the fact that Cyphal is positioned differently compared to other intravehicular communication technologies. Being a (near) zero-cost real-time distributed computing protocol, Cyphal differs from its alternatives, requiring the engineer to adopt a slightly different mindset when designing intravehicular networks. A simplified representation of different tiers of abstraction is summarized in the following table:
| Level of abstraction |
Design focus |
Basic information unit |
Examples |
| Distributed computing |
Network services |
Domain object |
DDS, CORBA, ROS graph, Cyphal
|
|
Databus (logical) |
Data packets |
Set of numerical values |
MODBUS, J1939, CANopen, AFDX |
| Multiplexed digital signaling |
Physical wiring |
Scalar signal |
ARINC 429, NMEA 0183, DShot |
| Analog/discrete signaling |
Physical wiring |
Scalar signal |
Analog ports, GPIO, RCPWM |
Expanding upon prior explanation, a network service specification is an abstract blueprint, focused on high-level behaviors and contracts that do not define the means of its implementation. Implementing the said behaviors and contracts such that they become available to consumers is referred to as service instantiation. Instantiating a service necessarily involves assigning its subjects and Cyphal-services certain specific port-identifiers at the discretion of the implementer (for example, configuring an air data computer of an aircraft to publish its estimates as defined by the air data service contract over specific subject-IDs chosen by the integrator).
Excepting special use cases, the port-ID assignment is necessarily removed from the scope of service specification because its inclusion would render the service inherently less composable and less reusable, and additionally forcing the service designer to decide in advance that there should be at most one instance of the said service per network. While it is possible to embed the means of instance identification into the service contract itself (for example, by extending the data types with a numerical instance identifier like it is sometimes done in DDS keyed topics), this practice is ill-advised because it constitutes a leaky abstraction that couples the service instance identification with its domain objects. Continuing with the air data computer (ADC) example, one could assume that multiple ADC may be differentiated by a dedicated numerical ID, but this would come at a cost of polluting the application data with unrelated implementation support details and forcing the service designer to determine the allowed composition strategies.
The “special use cases” mentioned above – where a service specification dictates a specific way of its instantiation – occur when enforcing a single rigidly-defined instance-per-network aligns with the domain (business) objectives. This circumstance is rare in practical systems and many of the services that would be candidates for such special methods are already provided by the standard data types. Such single-instance services are called singleton services, borrowing the term “singleton” from the theory of object-oriented programming. The following practical rules of thumb are recommended for deciding if a singleton service is advised:
- The service is not related to monitoring or controlling a physical process or interacting with the real world. This rule excludes sensor feeds, control loops, etc.
- The service is related to facilitating the process of distributed computing itself. This rule admits auxiliary functions like logging (
uavcan.diagnostic.Record), node status monitoring (like the standard Heartbeat or vendor-specific extended monitoring services), file transfer (uavcan.file.*), firmware update, etc.
Singleton services are facilitated by the DSDL feature of fixed port-ID: the service designer can explicitly express the fact that the service that is built on top of a particular data type is a singleton by specifying a particular fixed port-ID. Keep in mind that the space of fixed port-ID is tightly regulated by the Cyphal maintainers to avoid conflicts and promote interoperability – the details are provided in the Cyphal Specification. The list of well-known TCP/UDP port numbers offers a convenient analogy: defining a fixed port-ID is like claiming a specific TCP/UDP port number for a standard application, like HTTP server or NTP.
A service may be designed in such a way where it is provided by a group of identical collaborating agents with strong logical cohesion. In this case, we admit that the means of differentiating said identical agents from each other belong to the business domain, and as such, the service specification should contain the necessary provisions for that. We call such designs multi-agent services. Observe that this is not related to the concept of singleton service. A network may contain multiple instances of a multi-agent service where each instance is provided by an independent group of strongly logically bound agents. As a practical example of a multi-agent service, consider the propulsion system of a quad-plane VTOL: the propulsors creating lift in the hover mode belong to one multi-agent propulsion service, each propulsor being modeled as a separate service agent; the propulsors creating thrust in the forward flight belong to the second multi-agent service. In this example, the service consumers are unaware of which Cyphal nodes implement which propulsor agent – each agent could be a dedicated ESC/FADEC, or they all could be managed by a single hardware unit, or something in between.
The architectural difference between a regular service (we call it “generic service” here to avoid ambiguity) and a singleton service is formally illustrated by the following UML model:
Observe that relying on node-IDs to differentiate the service instances or agents would be a mistake for two reasons. The first reason is that a node-ID, per the Cyphal network model, is a transport-layer property that exists primarily to facilitate the operation of the network itself rather than to enrich the application-level contracts. Relying on the node-ID to define application-level functions constitutes a leaky abstraction throughout the layers separating the application and the transport. The second reason is that such separation presumes that each service instance or agent should be implemented by a separate node, which is not an adequate assumption for a service designer to make.
An attentive reader here might notice that Cyphal-services (not “architectural services” but “services as opposed to subjects”) are inherently bound to node-IDs and as such their ability to participate in well-architected network services is limited. This is a correct observation. This design is one manifestation of Cyphal’s commitment to providing powerful abstractions at zero cost – occasionally, certain trade-offs have to be made. Many practical services will be designed based on subjects alone without relying on Cyphal-services at all.
The principles explained in this section are generally referred to as the principles of semantic segregation because they dictate that service decomposition should be done based on the domain logic and business objectives rather than the envisioned means of implementation. The service instantiation is delayed until the system definition time and it can be effectively imagined in the form of a table that ties together specific services, their ports, and their port-identifiers. For example:
| Subject-ID |
Type |
Subject description |
Part of service |
| 4003 |
vendor.camera.Image.1.0 |
Left camera image |
Visual perception feed |
| 4004 |
vendor.camera.Image.1.0 |
Right camera image |
Visual perception feed |
| 200 |
vendor.battery.Status.1.0 |
Main battery status |
Power management |
| 201 |
vendor.battery.Status.1.0 |
Payload battery status |
Power management |
| 3000 |
vendor.geometry.geo.Position.1.0 |
Estimated GNSS position of the vehicle |
Navigation |
| 3001 |
vendor.sensor.gnss.Status.1.0 |
GNSS fix status of the above |
Navigation |
| 3010 |
vendor.geometry.geo.Pose.1.0 |
Estimated position and orientation of the vehicle |
Navigation |
| 3100 |
vendor.geometry.geo.Pose.1.0 |
Target position and orientation of the vehicle |
Navigation |
It follows that particular hardware or software units that are involved in distributed computing require configuration that cannot be known in advance until the unit is integrated into the network. Considering the described methods undesirable for high-integrity systems because of the perceived configuration complexity, would be a mistake because the configuration is defined and established exactly once at the system definition time rather than dynamically, and as such, the increase in complexity is marginal to nonexistent.
The negative examples given in this section are purposefully kept simple. One should recognize that the costs associated with suboptimal architectural choices tend to increase drastically with the complexity of the services or their applications.
Historically, various cultures on our planet have relied on different systems of measurement, which has resulted in a certain amount of turmoil due to either incompatibility of such ad-hoc systems between each other, or their lack of inner consistency. The worldwide process of metrication has largely eradicated this problem, especially in science and engineering, with some exceptions.
Inconsistent use of the systems of measure has been known to occasionally cause catastrophic failures, including the famous cases of the Mars Climate Orbiter or the Gimli Glider. Such issues are cheap to avoid by enforcing consistency across the board.
Cyphal requires that every data item should use one of the base or derived units of the International System of Units. Occasionally, this may result in the units that feel unfamiliar (e.g., kelvin instead of degrees, coulomb instead of ampere-hours, pascal instead of bars, radian/second instead of RPM, etc.), but this is not considered to be a problem because in the machine-to-machine interfaces consistency and standard-compliance far outweigh whatever personal discomfort the designer may perceive. Should it be desired to perform the unit conversion for the convenience of the human operator, it should be done by the end equipment exclusively.
As dictated by the specification, metric scaling is permitted, provided that the affected attributes are adequately suffixed. Scaling coefficients that are not multiples of 1000 should be avoided (i.e., centi, deci, deca, and hecto). The letter case of the suffix is independent of the attribute name suffix. The following example is nearly an exact copy from the Cyphal Specification – please read it for the background:
float16 temperature # [kelvin] No suffix because an unscaled SI unit is used.
uint32 delay_us # [microsecond] Scaled unit, suffix required. Mu replaced with "u".
uint32 MAX_DELAY_us = 90_000 # [microsecond] Notice the letter case.
float32 kinetic_energy_GJ # [gigajoule] Notice the letter case.