Yeah, this is basically what I had in mind.
As you said, I don’t think the message synchronization logic should be a part of the specification; rather, this is a piece of application-specific logic (although we should at least provide some generic implementation recommendations in the specification, perhaps). We should, however, provide our libraries with decent implementations of multisubject synchronizers. Luckily, the synchronization logic is invariant to the particular data types used, so it should be trivial to implement using available means of metaprogramming (barring inherently limited languages like C), without the need to pose any specific requirements to the synchronized messages (I don’t think it’s necessary to put timestamp first, because the ordering of the fields concerns only the serialization layer).
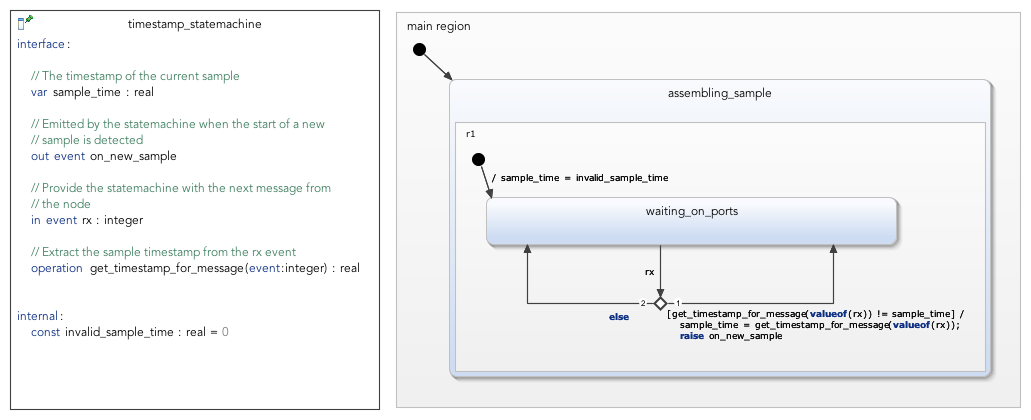
As I see it, such a multisubject synchronizer would be instantiated by the user with a set of subject IDs and their corresponding data types. The synchronizer then would expect that the timestamp information is provided in a field bearing a particular name and type (e.g. uavcan.time.Point timestamp); alternatively, we could allow some variance here by letting the user override the default name of the timestamp field per data type, if necessary. The synchronizer then would subscribe to each subject and collect messages; once a full set of messages under the same timestamp is collected, the full set is delivered at once (synchronously) to the application.
It would be desirable to implement additional user-selectable error handling policies (as you mentioned), such as:
- Allowing the synchronizer to maintain several simultaneous sets concurrently (the maximum number of concurrent sets is to be configurable), allowing it to correctly reassemble message sets even if some of them are interleaved with adjacent sets. For example, let
1 be a message belonging to the first set, 2 be the message belonging to the next set, and so on (assuming 4 subjects per set here):
1112123322334...
^ ^ ^
| | |
| | third set completed
| second set completed
first set completed
- Allowing the synchronizer to report incomplete sets rather than trying to complete delayed sets retroactively:
1112123322334...
^^ ^ ^^ ^
|| | || |
|| | || third set completed properly
|| | both ignored
|| second set reported while incomplete
|late message ignored
first set reported while incomplete
I imagine the following C++ interface to be an adequate representation of this logic, and I don’t foresee any implementation difficulties here, even if we had to be stuck with C++98 (although things would get a bit ugly):
void callback(const MessageTypeA& foo,
const MessageTypeB& bar,
const MessageTypeB& baz, // (not a typo)
const MessageTypeC& zoo)
{
// ...
}
constexpr auto NumConcurrentSets = 3;
auto synchronizer = MultisubjectSynchronizer<NumConcurrentSets>(
std::make_tuple(MessageTypeA, subject_id_foo),
std::make_tuple(MessageTypeB, subject_id_bar),
std::make_tuple(MessageTypeB, subject_id_baz), // (not a typo)
std::make_tuple(MessageTypeC, subject_id_zoo)
);
synchronizer.setCallback(callback);
Although the metaprogramming facilities of Rust seem to be quite limited, I don’t anticipate much difficulty there either.
I realize now that I’m confused about our new terminology. Do Ports carry Messages or are Ports synonymous with Messages?
The set of Ports contains both Subjects and Services. A Subject ID is also a Port ID, a Service ID is also a Port ID. As we’re talking only about messages here, we don’t have to use Port at all, for clarity and specificity.
 dangerous, especially those that overflow every 16 seconds.
dangerous, especially those that overflow every 16 seconds.