I am trying out the example class FirmwareLoader for handling background SW loading process.
During my SW update process, i.e. file.Read is fetching file from service every 50ms, I notice sometimes that status_ = ErrorTimeout in service response callback, even though all frames was actually sent on the bus (confirmed sniffing with GUI tool and separate CAN dongle) nehce completing both request and response on file.Read. The file.Read timeout is set to 5 sec, but all frames are sent on bus within much shorter time.
I am running the FirmwareLoader in main Node thread, so not much else is going on in that thread. My SubNode thread is casuing injected TX frames at the smae time and I can see a pattern when problem occurs. It happens when my node is broadcasting and invoking other nodes services at the same time.
I am thinking that there is a buffer issues somewhere but I have not figured out where. I am running on a Debian machine.
Adjusting socketcan txqueuelen does not make a difference.
Both threads are calling spin(50ms).
Any ideas what casing the file.Read timeout?
I am currently doing some trial and error to pinpoint the cause…
Your RX queue is getting overrun, probably. Since you are using SocketCAN, you should make sure that all your frames get delivered to the application. Launch the UAVCAN GUI tool on your SocketCAN interface and make sure that all your frames are still there. If they are, consider dumping all incoming frames from your application to make sure none are lost in its internal buffers.
I am now running candump om target that has the timeout issue, and compare it with GUI tool that runs the .file servcie and bus monitor. I will try comparing them to see if frames are lost.
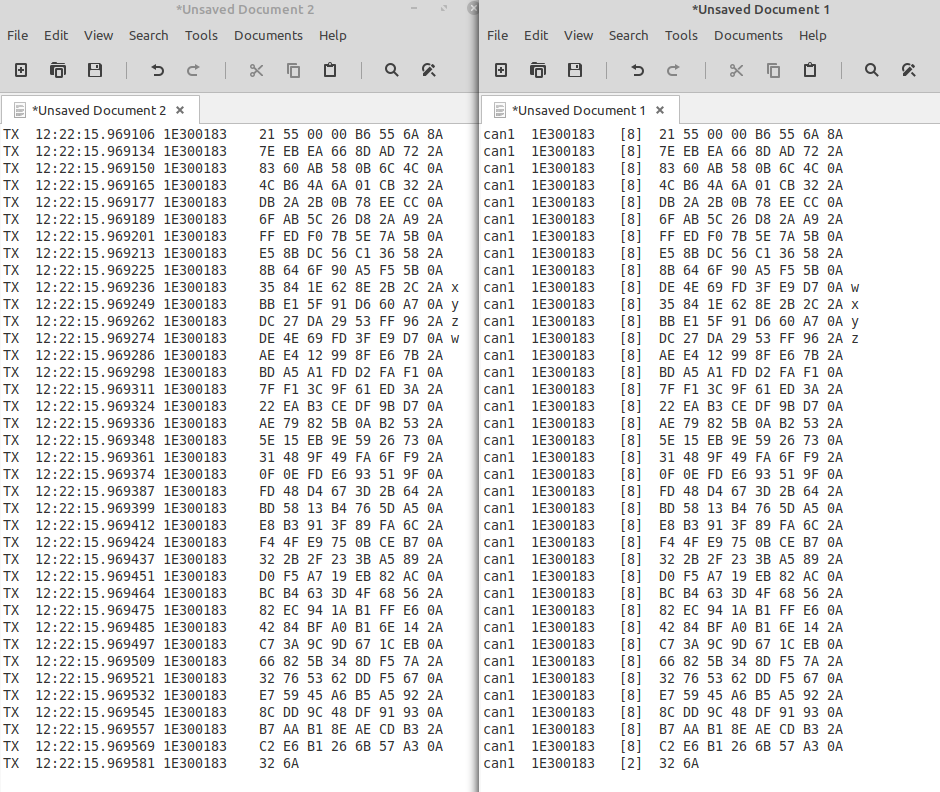
I discovered that response frames are reordered on target side, were file.Read was issued. In attached image, on left side, is the GUI tool bus monitor results on the file.Read response (service on PC). On right side is the candump result on target side.
I have marked the rows with x, y, z, w to indicate that the order is wrong on target side.
I guess the reordering might happen on both sides? Nevertheless, it does not follow spec: "All frames of a multi-frame transfer should be pushed to the bus at once, in the proper order from the first frame to the last frame."
As a reference test, I setup a passive node between file server and target.
So a PC with can dongle is listening on bus with GUI tool and monitors bus traffic between a file server node (on different hardware) and file read client (target).
I can be shown on the passive monitoring PC that frames are in correct order, by looking at the toggle bit. And the file.Read respons can be decoded properly. But target still times out sometimes.
That concludes that frames are re-ordered on response receiving side (target). And since candump shows exactly that, as seen above, the reorder takes place below uavcan stack…
What can be the cause of this?
Perhaps multiple RX buffers?
Sorry, I was referring to the CAN hardware. I suspect that its low-level driver is misbehaving, hence the reordering. From your answer I expect that it’s some kind of embedded system with a low-level interface between the CPU and the CAN controller, like SPI?
I am not sure… I have to investigate and come back to you. My guess is that lowering the bitrate might solve the issue. But that is not my primary solution at this point.
My FirmwareLoader is running in main Thread while other lower prio boradcasts and services are managed in SubNode thread. I notice that if I throttle the SubNode flushing, i.e. tx_injector.injectTxFramesInto(...) in main thread, I can work around this issue.
I modify the flushTxQueueTo(...) function to only inject one SubNode frame in each call, no while() loop for flushing everything. The main thread is only blocking with spin() for 1-2ms instead to ensure injected frames does not stay in queue for too long. This is ofcource a workaround until figured out the root cause…
I do not know it the original flushing puts a heavy load on lower drivers (perhaps because of loopback?) and in turn causes misbehaviour in onloading RX buffers…
Eh, I guess you can’t avoid digging into the driver implementation to fix this properly. I don’t know the specifics of your system, perhaps you could consider using a dedicated USB-CAN adapter that isn’t broken?
I believe my USB-CAN adapter is working properly…
And yes, it smells as a driver issue. While diggin into that, I am working on a solution to get around this.
Do you see any problems with modifying the flushTxQueueTo(...) as: