From Scott
Sticking with the simple example for now:
Given dsdl/VarArray.1.0.uavcan as
uint8 [<=16] data
import pyuavcan, dsdl
data = list(range(254,254-14,-1))
print('input : {}'.format(data))
input : [254, 253, 252, 251, 250, 249, 248, 247, 246, 245, 244, 243, 242, 241]
var_bits = pyuavcan.dsdl.serialize(dsdl.VarArray_1_0(data))
bit_string = next(map(lambda x: bytes(x).hex(), var_bits))
print(bit_string)
bytes_array = []
for i in range(0, len(bit_string), 2):
bytes_array.append(int(bit_string[i:i+2], base=16))
# raw value (what goes on the wire in the current implementation)
print('hex: {}'.format(['{:02X}'.format(x) for x in bytes_array]))
print('dec: {}'.format(['{}'.format(x) for x in bytes_array]))
77f7efe7dfd7cfc7bfb7afa79f9788
hex: [‘77’, ‘F7’, ‘EF’, ‘E7’, ‘DF’, ‘D7’, ‘CF’, ‘C7’, ‘BF’, ‘B7’, ‘AF’, ‘A7’, ‘9F’, ‘97’, ‘88’]
dec: [‘119’, ‘247’, ‘239’, ‘231’, ‘223’, ‘215’, ‘207’, ‘199’, ‘191’, ‘183’, ‘175’, ‘167’, ‘159’, ‘151’, ‘136’]
# This is what is implemented
data_reconstructed = []
# First 5 bits are the fill
fill = (bytes_array[0] & 0xF0) >> 3
print('fill should be {} is {}'.format(len(data), fill))
# This means the fill field starts at bit 3 which violates LSB rules.
for i in range(1, 15):
# Each element is then made out of the lowest 3 bits of the previous byte
# and (OR) the last 5 bits of next byte. This means the next element begins at
# bit 3 which, again, violates LSB rules.
bte = (bytes_array[i - 1] & 0x7) << 5 | ((bytes_array[i] & 0xF8) >> 3)
data_reconstructed.append(bte)
print(data_reconstructed)
fill should be 14 is 14
[254, 253, 252, 251, 250, 249, 248, 247, 246, 245, 244, 243, 242, 241]
# This is what we expect
data_reconstructed = []
# The fill begins at bit 1 per LSB format
fill = bytes_array[0] & 0x1F
print('fill should be {} is {}'.format(len(data), fill))
for i in range(0, 14):
# Each element in the array begins at bit 5 of a byte and then continues
# from bit 0 in the next byte.
bte = ((bytes_array[i+1] & 0x7F) << 3) | ((bytes_array[i] & 0xE0) >> 5)
data_reconstructed.append(bte)
print(data_reconstructed)
fill should be 14 is 23
[955, 895, 831, 767, 702, 638, 574, 510, 445, 381, 317, 253, 188, 68]
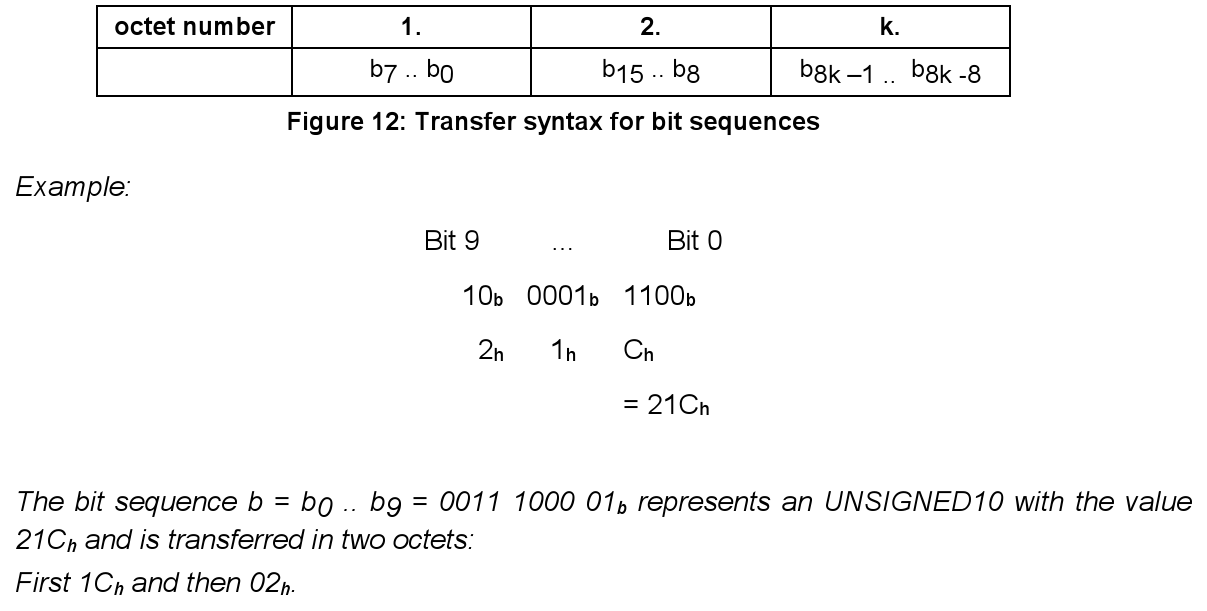
The Intel format (little-endian rules):
- Bytes are ordered LSB
- Bits are ordered LSB
- Parts of the bytes are ordered LSB – UAVCAN has a bug in this rule by placing fractional byte fields in Motorola format (big-endian). We followed rules 1 and 2 above (so bits inside those fractional byte fields are LSB), but we wrongly selected which part of byte to occupy by the fractional byte field (and the rest of following data).
Our experience has been that this implementation is incompatible with all known CAN databases and vendor tools for processing frames.