Integration of custom DSDL into one’s build system presents certain difficulties that in some cases appear to be avoidable. While for a large project these are insignificant compared to the overall efforts required to manage a sizable codebase, smaller projects and those of experimental variety could benefit from an alternative approach with better UX. In a recent pull request to 107-Arduino-UAVCAN by @aentinger we discussed the possibility of building a trivial web service that would allow one to upload an arbitrary DSDL namespace (as an archive or as a link to GitHub) and get generated code back:
The service would act not only as an approachable way of using DSDL but also as a GUI for Nunavut, showing one which flags to use to get the desired result.
We have the resources necessary to get this deployed and maintained, but we lack the resources necessary for implementing the business logic. We are therefore looking for a contributor experienced in web design who could undertake this and dedicate a couple of man*weeks to this project. Please reply here or send me a direct message if interested.
I’m interested - this sounds like a cool project to undertake. I have a decent amount of experience in full-stack web design; however, I’m not all that familiar with DSDL or Nunavut - I’d have to do more reading.
What features does this web service need to have? Just one place to upload a .zip archive or git repository link and then get back a zip of generated code? Any requirements for the stack (frontend framework, backend framework)?
Also, what are the time commitments for this project? Is there a set deadline?
Thankfully, this is the easy part because the code generation task is entirely managed by Nunavut. Look, suppose we have a DSDL namespace containing one type like this:
If the namespace directory is dsdl_src/my_project (which means that the file is dsdl_src/my_project/MyMessageType.1.0.uavcan), we invoke Nunavut as follows:
nnvg --target-language c --target-endianness=little --enable-serialization-asserts dsdl_src/my_project
The following options are to be configured by the user:
--target-language – currently, we support only C, but @scottdixon is working on supporting C++, and the Python support is implemented in an external library, pending its migration into Nunavut.
--target-endianness=little – there are three options to be selected by the user: little (default), any, big.
--enable-serialization-asserts – should be enabled by default.
Nunavut will store generated code into ./nunavut_out/ by default, along with the auxiliary support headers:
$ tree nunavut_out
nunavut_out
├── my_project
│ └── MyMessageType_1_0.h
└── nunavut
└── support
└── serialization.h
The entire output directory is then to be zipped and returned to the user. Observe that in DSDL, unlike most computer languages, the smallest unit of translation is not a file but a namespace directory — it is not possible to transpile a single type.
Some namespaces may depend on other namespaces (e.g., if your custom data type includes a standard data type from the uavcan namespace). This is handled by supplying Nunavut with --lookup arguments:
nnvg --target-language c --enable-serialization-asserts dsdl_src/my_project --lookup public_regulated_data_types/uavcan
But the thing is that when you generate code from scratch, you will have to generate it for every looked-up namespace as well because generated code for your namespace will depend on the generated code from the look-up namespace. So what I suggest is that the user is allowed to upload multiple namespaces in a single archive (or provide multiple links to GitHub repos), and then they are all compiled together by invoking Nunavut multiple times with the --lookup argument set to all of the provided namespaces. For example, if the archive contains foo/ and bar/, the commands are:
nnvg --target-language c --enable-serialization-asserts archive/foo --lookup archive/foo --lookup archive/bar
nnvg --target-language c --enable-serialization-asserts archive/bar --lookup archive/foo --lookup archive/bar
Handling GitHub links (or any external links to zip archives) is easy, you can just copy-paste the implementation from here:
If the user supplied a repo link like https://github.com/UAVCAN/public_regulated_data_types/, it is either automatically converted into https://github.com/UAVCAN/public_regulated_data_types/archive/master.zip or a Git client is invoked to clone the repository (the former is probably easier but the default branch name has been recently changed to main which may complicate things).
Yes, but there also needs to be a couple of options as I mentioned above: select target language (currently only C; I’m not sure but @aentinger might want to add a separate target language for Arduino), select endianness, and assertion checks.
It is best to avoid a step-through, wizard-style interaction because it will turn tedious fast. It’s best to make it entirely single-page, I think, where you can just tweak settings and run generation without clicking through different views.
When invoking Nunavut, the used command-line arguments should be shown to the user to simplify the transition from using the web service to running Nunavut locally.
There are no hard requirements but we internally use Python a lot, so it’s best to write the backend in that. For the front-end, we are mostly indifferent but I know that @scottdixon loves Vue.
There is no strict deadline but the sooner the better. I will try to provide prompt answers to avoid blocking your work on this.
I recommend starting in your personal GitHub repository which we will transfer over to UAVCAN afterward.
Yes, but there also needs to be a couple of options as I mentioned above: select target language (currently only C; I’m not sure but @aentinger might want to add a separate target language for Arduino), select endianness, and assertion checks.
Yes, I’d love to have a separate Arduino target language for nunavut so that users can easily the required headers for digestion by 107-Arduino-UAVCAN. I’ve summed up the requirements for said generator in a nunavut issue (Anyone with Python skills interested in this?). Regardless, this doesn’t change the requirements for the web-service at all as it’s simply an additional entry in a drop-down menu (or checkbox or …).
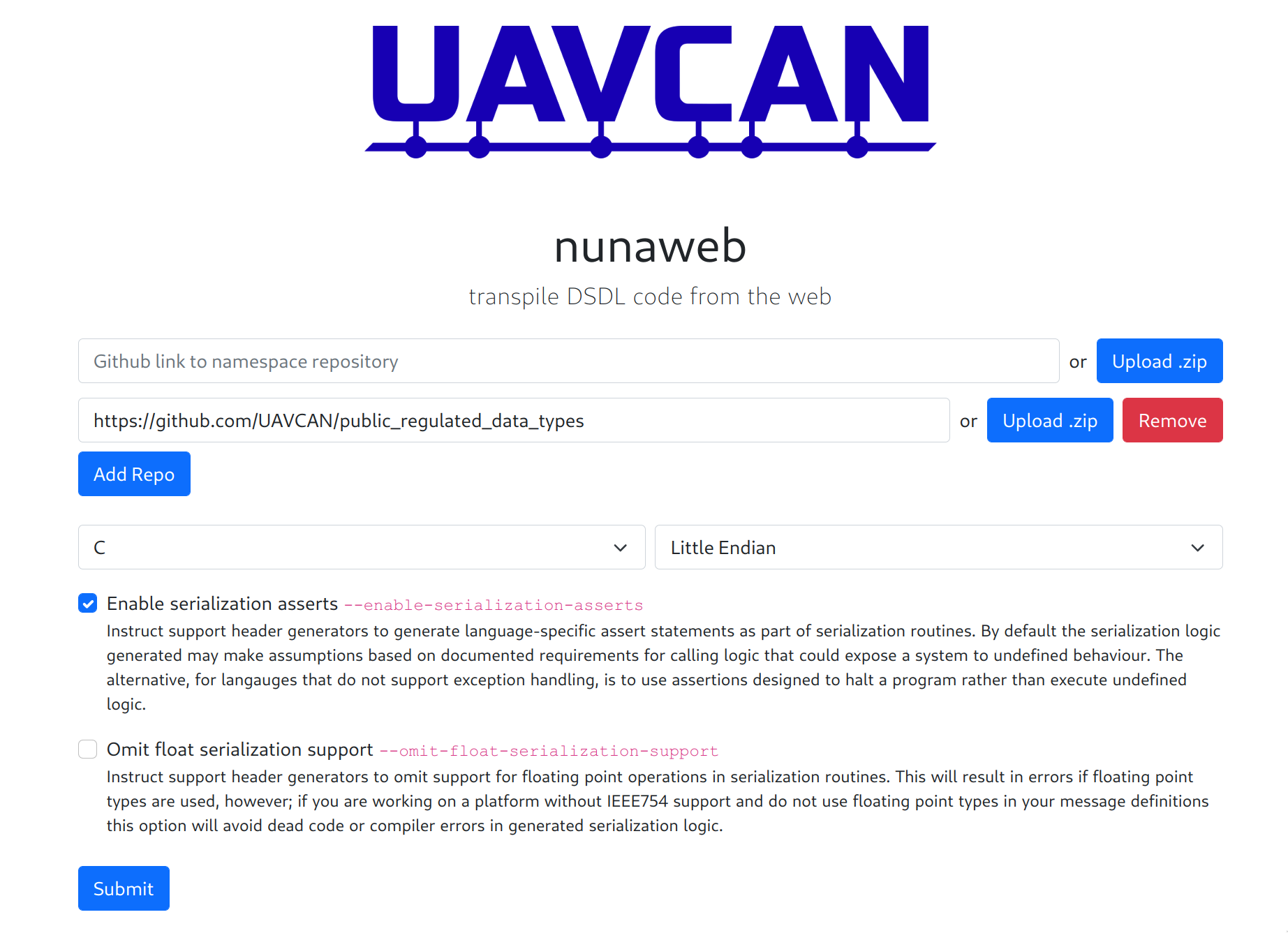
The webapp is comprised of a simple Nuxt.js frontend and a Flask+Celery[redis]+static file server backend. It is capable of taking either a Github link or an uploaded .zip archive containing DSDL namespaces and outputting a link to a generated .zip that the user can then download.
The advantage of this setup is scalability; the frontend is entirely decoupled from the backend, meaning the two can be scaled separately as needed. All components of the backend (Flask, Redis, Celery, static file server) can easily be scaled.
This should not be treated as the final version in any way. Major refactoring is in order (the code is extremely messy and there’s some parts that definitely need rearchitecting and/or rewriting), and both the frontend and backend concepts may be changed entirely.
That being said, give it a spin! Documentation for running the backend server is in a README; the frontend is just npm run dev.
This is wonderful. In addition to the feedback I provided via Slack, here are a few extra comments that I came up with after running the application locally.
While skimming through the sources I noticed that you invoke Nunavut as a library:
Maybe consider invoking the nnvg CLI tool instead (IIRC Celery provides some built-in means for that, right?) because it will allow you to display the usage example to the user, as I mentioned here:
While I got the app running, I couldn’t actually generate code for an unknown reason. After I click “submit”, the backend accepts the request but code generation doesn’t start:
Hi! Sorry for the late reply. Last week was a bit busy for me.
Maybe consider invoking the nnvg CLI tool instead (IIRC Celery provides some built-in means for that, right?) because it will allow you to display the usage example to the user, as I mentioned here:
There are a few issues with this, one major one being that it’s just not all that clean to execute an external script/executable from Python. I couldn’t find any Celery-specific utility for doing this, so the best we’d be able to do is a subprocess.Popen, which is kind of icky in general. Executing the script via CLI would also mean no progress updates, unless we parsed the CLI output to give us progress, updates, which is extremely icky.
The actual command has to be generated by the backend for security reasons (the only way we could guard against someone submitting a malicious command is basically parsing the command given to check that everything is valid, which is again very icky), so either way the outward facing API will likely not change, only the internals, which at that point I don’t really see a reason to make more work for what will essentially appear to be the same result.
What we could do instead is generate example usage text on the frontend to display to the user, and keep the backend interfacing with the library. The user will not notice any difference, and it will be significantly easier to maintain the backend.
While I got the app running, I couldn’t actually generate code for an unknown reason. After I click “submit”, the backend accepts the request but code generation doesn’t start:
I’ve included a docker-compose file for setting up a development environment which should eliminate any “it-works-on-my-machine” problems. It should set everything up and run all the miscellaneous needed servers for you on your system; all you need to do is run docker-compose up. It also has the added benefit that it can be fairly easily converted into a deployable production environment.
The code generation not starting issue is likely because the Celery server wasn’t started, but if not, then I’m not sure. Either way the docker-compose file should get rid of these kinds of issues.
First, backend testing would benefit from some automation
I definitely hear you on this. I haven’t worked with pytest and nox much, so I’m taking a look at those frameworks. Automated unit and integration testing is on the way soon
As for progress updates this week, both the frontend and backend have been refactored a little to be cleaner, and to allow for multi-repo generation, which I just added. Allowing multiple repos exposed some previously unseen bugs regarding error handling etc, so those are fixed too.
At this point, I think we’re basically done with the main features. All that remains is some more refactoring to improve code readability, maintainability and scalability, as well as proper unit and integration tests. We should be ready to deploy soon
Re: generating the nunavut command on the frontend, I’m actually not fully sure if it’s a good idea, as it requires us to get a directory of files for each zip archive (so we can find the actual DSDL repository names). While this shouldn’t be a major issue for uploaded zip archives, remote links (e.g. the public_regulated_data_types) may have issues.
I think the approach we should take here is to generate the nunavut command on the backend, before starting the actual generation. This will allow us to generate something that matches the backend environment as closely as possible, while also solving the aforementioned frontend-only generation problems.
Note that it can take several seconds for the server (at least testing on my computer) to fetch the remote namespace. Fetching namespaces on both the frontend and the backend is pretty inefficient.
I hear you regarding the nnvg invocation. Let’s do it as you suggested.
Regarding the new interface: I see that you’ve split the sources into two groups, but are you sure it’s better than keeping them all at the top of the page, uniformly styled?
The main disadvantage is that it kind of clutters the UI a bit, but it’s not a big deal. My main thought process here was that the majority of beginner users (which are the target user demographic for this app) will only be uploading their repo with a couple of namespaces in it, linked against the public data types.
If we want multi-repo selection to be more prominent, then this proposed UI change would accomplish that.
Yes, I think your updated UI suits the typical workflow better. I would also recommend renaming “Add Repo” into “Add namespaces” (plural because one .zip or repo may contain multiple namespaces) to be more specific.
Update here. All the main features (multi-repo upload, flag and target options, async task queue with Celery, error handling etc.) are done. There are still a few necessary things to implement in preparing this for production (e.g. rate limiting for the backend), but these shouldn’t be too hard - if everything goes right this should be deployable by the end of the week.
The main outstanding tasks right now are:
API rate limiting for the backend
Bundle optimization for the frontend
Move fetching remote repository tasks to Celery, as these can take a while (uploaded zips can be unpacked in the API route itself)
Possibly split the frontend into a couple more components to make the code cleaner (not urgent, can happen after deployment)
Unit tests for frontend and backend (can happen after deployment)
If there’s anything I missed in that list let me know.
All necessary components (rate limiting, bundle optimization, remote repo fetching -> Celery) have been implemented. The application should be ready to be deployed to production.
The unit tests will likely take a little while more, as I’m still trying to grapple with pytest+Jest and make them work. However, they should be up in a couple of days.
Great. I just sent you an invite to join the UAVCAN org on GitHub. I suggest we transfer the repository from your private account over to the org, but before we do that, can you please add a license file to the repository? We typically use MIT or hybrid Apache/MIT.
@clydej can you please coordinate with @bbworld1 to see Nunaweb deployed to production? I imagine that we should provision an extra AWS instance for this and put it on a subdomain like nunaweb.uavcan.org. We are going to need CD as well.
@bbworld1 do you have an estimate of the required RAM for the instance? Do you think t3.small is an adequate instance type to start with? Maybe we will find out as we go.
I can transfer the repository and create an new AWS instance for the web app. @bbworld1 let me know once the license file has been added to your repository, and I will start work on this.
I have deployed nunaweb to our new vm in Estonia at nunaweb.uavcan.org. However, when I try to upload a test .zip file (my_project.zip), the web app does not respond. I have logged an issue in GitHub (#2). It could be an application or configuration issue.